

【AWS re:Invent 2025】大規模なデータベースパフォーマンス問題のトラブルシューティング|講演レポート
AWS re:Invent 2025とは?
AWS re:Invent 2025は、2025年12月1日~5日にかけて米国ラスベガスとオンラインにて開催される、AWS主催の世界最大級クラウドコンピューティングカンファレンスです。
本イベントでは、世界中のクラウドコミュニティが一堂に会し、未来を築くための最新技術や専門家によるセッション、そして多彩なネットワーキングの機会が提供されます。
AWSのリーダーたちがクラウドの未来を形作る最新の発表やビジョンを共有する「基調講演」、AWSヒーローやコミュニティリーダーが主導する60以上の「学習セッション」や300社以上が出展するExpoを通じて、実践的な知識とスキルを深めることができます。
セッション概要
本講演では、大規模なデータベース群を管理する中で、根本原因を迅速に特定するための統一されたアプローチが紹介されました。
| セッション番号 | COP331 |
|---|---|
| セッション名 | Troubleshooting database performance issues at scale(大規模なデータベースパフォーマンス問題のトラブルシューティング) |
| セッション概要 | 大規模なデータベースフリートを管理するには、数百のインスタンスの中から問題のあるインスタンスを1つでも見つけ出し、それが顧客に影響を与える前に対処する必要があります。 このライトニングトークでは、多様なAuroraおよびRDSデータベースエンジンにおけるパフォーマンスのボトルネックを迅速に特定し、解決する方法を紹介します。CloudWatch Database Insightsを活用したフリート全体のモニタリング、実行計画とロック分析によるSQLレベルの診断、そしてパフォーマンス傾向分析の方法を学びます。 このセッションでは、アプリケーションシグナルとデータベースメトリクスの相関関係、スロークエリの分析、パフォーマンスのトラブルシューティングワークフローなど、実践的な手法を紹介します。 |
大規模DBは、なぜ障害原因の特定が難しい?
このセッションでは、聴衆が課題を自分ごととして捉えやすいよう、Alexという架空の人物が登場します。彼はとある会社で働くSREのリーダーで、日々データベースの安定稼働に責任を負っています。
彼が直面する最大の課題は、アプリケーションチームから寄せられる「サービスが遅い。きっとデータベースが原因だ」という漠然とした報告です。問題が本当にデータベースにあるのか、それともアプリケーション側にあるのか、その切り分けに多くの時間を費やしてきました。
この問題の根源には、多くの企業に共通する「情報の断絶」があります。
| チーム | 見ている世界 | 抱えている疑問 |
|---|---|---|
| アプリケーションチーム | サービスの機能や応答速度を監視。「ユーザーのこの操作が遅い」ことは分かる。 | 「データベースの中で何が起きていて遅いんだろう?」 |
| データベースチーム(Alex) | データベースのクエリ実行や負荷を監視。「このクエリが重い」ことは分かる。 | 「そもそも、なぜアプリはこのクエリを今、大量に実行しているんだろう?」 |
このように、それぞれのチームが使うツールや見ている情報が異なるため、互いの状況が分かりません。データベースチームのAlexには、アプリケーションで「何が起きているのか」というコンテキスト(文脈)が決定的に不足しています。
情報の断絶が生む、2つの課題
このような「情報の断絶」は、Alexのような運用担当者にとって、主に2つの課題を生み出しています。
多様なデータベースとツールが乱立する
Alexが管理するのは、PostgreSQL、MySQLなど多種多様なデータベースです。それぞれに専用の監視ツールが存在するため、情報を横断的に見ることが難しく、問題解決の複雑さに拍車をかけています。
問題の切り分けに時間がかかる
アプリケーションのコンテキストが分からないため、データベースの負荷上昇が、本当にデータベース自体の問題なのか、それともアプリケーションからの予期せぬリクエストが原因なのかを判断するのに時間がかかります。
本講演で紹介されたのは、これらの課題を解決するための、AWSの統合監視ツールを活用した3ステップのトラブルシューティング・ワークフローです。
【Step1】ツールの乱立を解決、DB群から問題の1台を特定
課題解決の第一歩は、広大なデータベース群(フリート)から問題のインスタンスを特定することです。そのために活用するのが、Amazon RDSの標準機能「Performance Insights」のフリート監視ダッシュボードです。
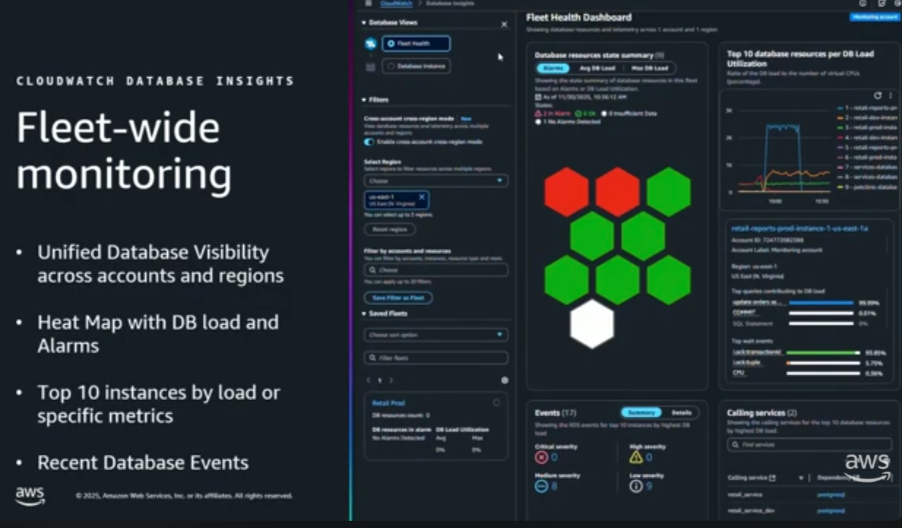
フリート監視ダッシュボードのイメージ
これは特別な設定は不要で、各データベースでPerformance Insightsを有効にするだけで、複数のアカウントやリージョンにまたがるDB群を一元的に把握できます。
Alexは「リテールサービスが遅い」との報告を受け、まずこのダッシュボードを確認。色分けされた負荷状況(ハニカムビュー)やCPU使用率トップ10リストを使い、無数のDBの中から、異常な負荷を示す問題の1台を瞬時に特定しました。
【Step2】DB内部を深掘り、ボトルネックを診断
問題のインスタンスを特定したら、次はPerformance Insightsを使い、その内部を深掘りしてボトルネックを診断します。
このステップの鍵は、収集したパフォーマンスデータを、さまざまな切り口で分析することです。講演では、Alexが直面した3つの典型的なシナリオを通して、具体的な診断方法が紹介されました。
シナリオ1. 高負荷クエリの原因を「スライス機能」で追跡
| 概要 | 詳細 |
|---|---|
| 課題 | 「リテールサービスが遅い」原因となっていた高負荷クエリ。しかし、誰が、どこから、なぜ実行しているのか不明。 |
| 解決手順 | Performance Insightsのメイングラフに対し、「Slice by」(スライス)機能を適用。 1. 「User」(ユーザー)でスライスし、実行者を特定 2. 「Host」(ホスト)でスライスし、実行元マシンを特定 3. 「Application」(アプリケーション)*でスライスし、使用ツールを特定 |
| 診断結果 | 「DBAインターンが、特定のホストから、DB運用ツールを使って、高負荷クエリを継続的に実行していた」という具体的な状況証拠を掴んだ。 |
シナリオ2. 「ロック専用ビュー」でデッドロックを解析
| 概要 | 詳細 |
|---|---|
| 課題 | 「レポートが実行できない」という報告。データベース全体に多数のロックが発生しているが、根本原因が複雑で分からない。 |
| 解決手順 | Performance Insightsのロック分析専用ビューを活用。 1. 「Weights」(待機)ビューで、遅延がロック待機によるものだと確認 2. 「Blocked objects」などのタブで、ロックの根源となっているテーブルやセッションを絞り込み 3. 「lock tree」(ロックツリー)で、セッション間の依存関係を視覚的に解明。 |
| 診断結果 | コンソールから離れることなく、複雑なロックシナリオの根本原因を特定し、解消への道筋を立てることができた。 |
シナリオ3. 「プランビュー」で非効率なSQL実行計画を特定
| 概要 | 詳細 |
|---|---|
| 課題 | 「注文検索が、時間帯によって急に遅くなる」という報告。同じクエリなのに、なぜパフォーマンスが変動するのか不明。 |
| 解決手順 | グラフの表示モードを「Plan」(プラン)ビューに切り替え。 1. グラフが性能の異なる2つの実行計画に分離され、パフォーマンスの違いが一目瞭然に 2. 画面下部で詳細を比較し、非効率なプランでは「フルテーブルスキャン」が、効率的なプランでは「インデックススキャン」が使われていることを確認。 |
| 診断結果 | パフォーマンス劣化した原因は、意図せず非効率な実行計画に切り替わってしまったためである、と断定できた。 |
【番外編】その他の便利機能
講演では、Alexが直面した3つのシナリオ以外にも、日々の運用を効率化する便利な機能が2点紹介されました。こちらも有益な情報だと感じましたので、記載します。
| カスタムメトリクスダッシュボード | Performance Insightsには100以上のメトリクスが用意されています。講演では、その中から「平均Read/Writeレイテンシ」など、自分たちが重視する指標だけを集めたカスタムダッシュボードを作成するデモが紹介されました。 一度作れば、DBエンジンタイプごとに共通のビューとして利用でき、チームの監視レベルを標準化できます。 |
|---|---|
| スロークエリ分析 | 「時々遅くなるクエリがある」といった漠然とした問題に対し、スロークエリ分析機能が有効です。 実行に時間がかかったクエリをパターン別に集計し、最大実行時間や95パーセンタイル値などを一覧表示。これにより、これまで気づかなかったパフォーマンスのボトルネックを発見するきっかけになります。 |
【Step3】情報の断絶を解決、問題の真因を切り分ける
最後に、問題の切り分けに関する課題を解決します。ここで切り札となるのが、AWSのアプリケーションパフォーマンスモニタリング(APM)サービスである「Application Signals」との連携です。
「リテールサービスの問題は絶対にDBだ」という報告に対し、AlexはPerformance InsightsからApplication Signalsの画面に直接遷移。API GatewayからLambda、DBに至るエンドツーエンドの処理の流れを可視化しました。

エンドツーエンドの処理の流れを可視化する様子
その結果、DBの応答時間は正常である一方、Lambda関数のコードでエラーが発生していることを発見。これにより、問題の真因がDBではなくアプリケーションのコードにあることを明確な証拠をもって証明できたのです。
【Ops Today解説】プロアクティブな運用を裏付ける内容
この講演は、レベル300(上級者向け)の内容だけあって、運用現場のリアルな課題解決プロセスが提示されていました。筆者が特に重要だと感じた点を、2つ挙げます。
監視の限界と、可観測性の価値
これまでの障害対応は、「CPU使用率が90%を超えた」といった既知の異常(監視)をアラートで検知することから始まっていました。
しかし、Performance Insightsの「スライス機能」やApplication Signalsの「トレース」は、システム内部で何が起きているかを未知の観点から自由に問いかけ、探求することを可能にします。これは、単なる「監視」ではなく、システム内部の状態をどれだけ深く理解できるかという「可観測性(Observability)」の考え方そのものです。
「情報の断絶」という課題の本質は、各チームが持つシステムの「可観測性」が低かったことにあると感じます。この講演は、AWSのネイティブサービスだけで、その可観測性を飛躍的に向上させられることを証明していました。
プロアクティブな予防へのシフト
筆者がオープニング基調講演のレポートの「Ops Today解説」でも触れたように、今年のre:Inventでは、事後対応の「火消し」から脱却し、プロアクティブな予防へシフトするという思想が、複数のセッションに共通する考えになっているように感じます。
本講演で語られたPerformance Insightsの「スライス機能」やApplication Signalsによるエンドツーエンドのトレースは、基調講演で語られた抽象的なビジョンを具体化するための、実践的なツールキットになっていました。
また、これまでDB担当者はアプリを、アプリ担当者はDBを、それぞれブラックボックスとして扱っていたと思います。しかし、エンドツーエンドで繋がった今、「それは私の担当範囲外だ」という言い訳は通用しなくなります。
これからは「この共有された可視性を使って、我々はどうシステムを改善できるか?」が問われると感じました。
まとめ
このセッションで紹介されたトラブルシューティングのワークフローは、以下の4つのステップに要約できます。
| ステップ | アクション |
|---|---|
| 1. 特定 | フリートビューでデータベースインスタンスと負荷を特定する。 |
| 2. 分析 | インスタンスビューでクエリ、ロック、実行計画を分析し、負荷の原因を理解する。 |
| 3. 確認 | 主要なメトリクスを確認し、負荷との相関関係を把握する。 |
| 4. 連携 | APM(Application Performance Monitoring)を活用し、エンドツーエンドのトランザクションを分析して問題の切り分けを行う。 |
これらのステップを実践することで、大規模で複雑な環境においても、データベースのパフォーマンス問題を効率的かつ正確に解決に導くことができるはずです。ぜひご参考ください!

