

Google Cloudでプロアクティブ障害検知! 予兆検知・自動修復の構築方法
障害が発生する前にその兆候を掴み、システムが自ら問題を修復してくれる「予兆検知」と「自動修復」の実現は、多くの運用監視担当者やSREにとって望んでやまないものでしょう。
この記事では、障害の兆候を能動的に検知し対処するアプローチ「Proactive Failure Detection(プロアクティブ障害検知)」を、Google Cloudで実現する方法を解説します。
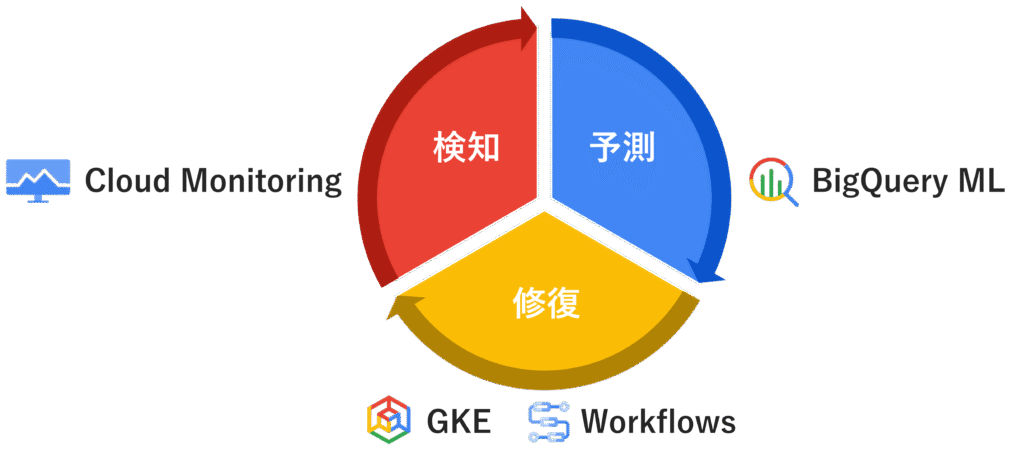
具体的には、「Cloud Monitoring」の異常検知や「BigQuery ML」といったAI/ML技術を活用し、システムの障害を予測する予兆検知を実現。「GKE」の標準機能や「Workflows」を用いた自動修復と組み合わせ、自律型運用を目指します。
予兆検知・自動修復がもたらす価値
AI/MLを活用した予兆検知と自動修復の導入は、言うまでもなく、大きなビジネス価値をもたらします。改めて、そのメリットを書き出してみます。
| メリット | 具体的な効果 |
|---|---|
| 可用性の向上 | 障害の発生を未然に防ぎ、サービス停止時間を大幅に削減。顧客満足度とビジネス機会損失の低減に貢献します。 |
| 運用コストの削減 | 障害対応にかかるエンジニアの工数を削減。アラート対応や手動復旧作業から解放され、より戦略的な業務に集中できます。 |
| エンジニアの負担軽減 | 深夜や休日の緊急対応が減少し、エンジニアのワークライフバランスが向上。創造的でやりがいのある業務への注力を促します。 |
| セキュリティの強化 | 不正アクセスの兆候や通常とは異なるAPIコールなど、セキュリティインシデントにつながる可能性のある異常を早期に検知できます。 |
予兆検知・自動修復の実現方法
Google Cloudは、予兆検知と自動修復を実現するための強力なサービス群を提供しています。ここでは、以下を組み合わせた予兆検知と自動修復の実現方法を、4つのステップでご紹介します。
- Cloud Monitoring による「検知」
- BigQuery ML による「予測」
- GKE の標準機能、Workflows による「修復」
1. Cloud Monitoringでリアルタイム異常検知

すべての基本は、信頼性の高いデータ収集から始まります。Cloud Monitoringの異常検知は、特別なエージェントの導入なしに、数クリックで設定を開始できます。
まず、Google Cloudコンソールの「Metrics Explorer」を開きます。ここで、監視したいメトリクス、例えば「GKEコンテナのCPU使用率」などを選択します。グラフが表示されたら、画面上部にある「Anomaly Detection」のトグルをオンにするだけで、過去のデータに基づいた正常範囲のバンドと、それを逸脱した異常点がグラフ上に可視化されます。
異常検知のアラート設定
次に、可視化された異常点をアラートに繋げます。グラフの右上にある「Save Chart」からアラートポリシーを作成する画面に進み、「Add Alert Condition」で先ほど設定した異常検知の条件を指定します。
ここで重要なのは、通知チャネルの設定です。メールやSlackへの通知に加え、「Pub/Sub」を選択することで、検知した異常をイベントとして後続の自動修復ワークフローへ連携できます。
Pub/Subトピックを指定すれば、異常検知時にそのトピックへ自動でメッセージがパブリッシュされる仕組みが完成します。この通知を、ステップ4で解説するWorkflowsで受け取ることにより、修復アクションが自動的に開始されます。
2. BigQuery MLで障害予測モデルを構築・実行

未来の障害を予測するには、まずCloud Monitoringから長期的なメトリクスデータをBigQueryへエクスポートする設定を行います。これは、ログルーターのシンク機能などを利用して、特定のメトリクスデータをBigQueryのデータセットへ継続的に流し込むことで実現します。
データが蓄積されたら、BigQuery MLで時系列予測モデルを作成します。これは、使い慣れたSQLで記述できます。例えば、instance_cpu_utilizationというテーブルにCPU使用率の時系列データが格納されている場合、以下のようなクエリで予測モデルを構築します。
CREATE OR REPLACE MODEL `my_project.my_dataset.cpu_utilization_forecaster`
OPTIONS(
MODEL_TYPE='ARIMA_PLUS',
TIME_SERIES_TIMESTAMP_COL='timestamp',
TIME_SERIES_DATA_COL='cpu_utilization',
TIME_SERIES_ID_COL='instance_id'
) AS
SELECT
timestamp,
instance_id,
cpu_utilization
FROM
`my_project.my_dataset.instance_cpu_utilization`;
モデルが完成したら、ML.FORECAST関数を使って未来の値を予測します。例えば、今後48時間分のCPU使用率を予測したい場合、以下のクエリを実行します。
SELECT
*
FROM
ML.FORECAST(MODEL `my_project.my_dataset.cpu_utilization_forecaster`,
STRUCT(48 AS horizon, 0.8 AS confidence_level));
この予測結果が「95%以上の確率でCPU使用率が90%を超える」といった条件に合致した場合に、Cloud FunctionsなどをトリガーしてPub/Subへ通知を発行し、プロアクティブな修復アクションへ繋げることが可能です。
3. GKEノード自動修復の有効化

「修復」のステップでは、まずインフラレベルで自己修復を実現するGKEの標準機能を見ていきます。
GKEのノード自動修復は、クラスタの作成時または更新時に簡単なコマンドで有効にできます。この機能は、GKEに標準で組み込まれているNode Problem Detectorと連携し、カーネルデッドロックやファイルシステムの破損といったノード自体の問題を監視します。
新しいクラスタで有効にする場合は、以下のコマンドを実行します。
gcloud container clusters create CLUSTER_NAME \
--enable-node-auto-repair \
--zone COMPUTE_ZONE
既存のクラスタで有効にする場合は、updateコマンドを使用します。
gcloud container clusters update CLUSTER_NAME \
--enable-node-auto-repair \
--zone COMPUTE_ZONE
この設定は、Google Cloudコンソールからも可能です。GKEクラスタの詳細画面から「ノードプール」を選択し、対象のノードプールの編集画面で「自動化」セクションにある「ノードの自動修復を有効にする」のチェックボックスをオンにするだけです。
これにより、GKEがノードの異常を検知した際に、自動でPodを安全に退避させた上でノードを再作成するプロセスが実行され、手動での介入なしにインフラレベルでの自己修復が実現します。
4. Workflowsによる自動修復の実践

より能動的で、アプリケーションの状況にも応じた柔軟な修復処理を実装したい場合、サーバーレスのワークフローオーケストレーションサービスであるCloud Workflowsが活躍します。
ステップ1や2で検知・予測したイベントをトリガーとして、具体的な修復アクションを自動で実行する仕組みを構築できます。
【例】自動修復シナリオのサンプル
例えば、Cloud MonitoringがGKEノードのメモリ使用量の逼迫を検知し、Pub/Subへ通知するシナリオを想定します。
このPub/SubメッセージをEventarcのトリガーが受け取ると、Workflowsが起動します。このワークフローでは、あらかじめ定義された手順に沿って、以下のような一連の修復処理を自動で実行できます。
- 【原因調査】 問題のノードを切り離し、調査用のスナップショットを取得
- 【ノードの隔離】 対象ノードをcordon(スケジュール不可)状態にし、新たなPodが割り当てられないようにする
- 【Podの再配置】 新しいノードを追加し、Podをそちらへ移動
以下は、Pub/SubメッセージをトリガーにGKEノードをドレイニング(Podの退避)する処理を呼び出すWorkflowsの簡単なサンプルです。
yaml
# main.yaml
main:
params: [event]
steps:
- decode_pubsub_message:
assign:
- message: ${base64.decode(event.data.message.data)}
- incident: ${json.decode(message).incident}
- log_incident:
call: sys.log
args:
text: ${"Incident received for resource: " + incident.resource.display_name}
# ここで、受け取ったインシデント情報(incident.resource.display_nameなど)を基に
# 修復対象のGKEノードを特定するロジックを実装します。
- get_gke_node_name:
assign:
- node_name: "gke-cluster-1-pool-1-xxxxxxxx" # 仮のノード名
- drain_node:
call: googleapis.container.v1.projects.zones.clusters.nodePools.update
args:
project: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
zone: "asia-northeast1-a"
clusterId: "your-cluster-id"
nodePoolId: "your-node-pool-id"
body:
# ここではAPIの例としてupdateを記載していますが、
# 実際にはgcloudコマンドをCloud Build経由で実行したり、
# Kubernetes APIを直接呼び出すステップを実装します。
# 例:kubectl drain ${node_name} --ignore-daemonsets
- log_completion:
call: sys.log
args:
text: ${"Node drain process initiated for " + node_name}
- return_result:
return: "Workflow completed"
このようにWorkflowsを使うことで、人手を介さずに障害を未然に防ぎ、安定したサービス提供を継続することが可能になります。
まとめ
この記事では、Google CloudのAI/MLサービスを活用した、障害の予兆を検知して自動で修復する(Proactive Failure Detection)方法を解説しました。
各サービスを組み合わせることで、システム自身が問題を解決する「自律型運用」への道が拓かれます。しかし、最初から完璧なシステムを構築する必要はありません。
まずはCloud MonitoringのAnomaly Detectionを有効にして、あなたのシステムのメトリクスに潜む異常を可視化するなど、できることからスモールスタートするのも良いでしょう。
そこから得られる気づきが、あなたの運用を次のステージへと進める、大きな一歩になるはずです。
