

【AWS Summit Japan 2025】公共機関におけるクラウドレジリエンス ~障害からより早く回復するシステムの作り方~ 講演レポート
AWS Summit Japan 2025 とは?
AWS Summit Japan 2025とは、アマゾン ウェブ サービス(AWS)が主催する日本最大級のクラウドコンピューティングイベントです。2025年6月25日(水)と26日(木)の2日間、千葉県の幕張メッセで開催され、オンラインでのライブ配信も行われます。
このイベントは、AWSに関する最新技術やベストプラクティスの共有、情報交換を目的としており、クラウドを活用したイノベーションに興味のある全ての人を対象としています。
セッション情報
| セッション名 | 公共機関におけるクラウドレジリエンス ~障害からより早く回復するシステムの作り方~ |
|---|---|
| セッション概要 | デジタル社会の実現に向け、政府・地方自治体・医療・教育など様々な公共機関の重要システムがクラウド上で稼働し、国民の生活を支える基盤として日々重要度が高まっています。 システム障害は国民生活に大きな影響を及ぼすため高い可用性が必要であり、障害から可能な限り早く回復するレジリエンス(回復力)を持ったシステムを構築することが重要です。 本セッションでは、公共機関におけるレジリエンスライフサイクルフレームワークを始めとするレジリエンス強化の具体的な考え方について解説します。 |
| 登壇者 | 讃岐 和広 アマゾン ウェブ サービス ジャパン合同会社 パブリックセクター技術統括本部 CSM・パートナー・スケールソリューション技術本部 パートナーソリューション部 シニアパートナーソリューションアーキテクト |
セッション詳細
本セッションでは、公共システムにおけるクラウドレジリエンスの重要性を理解し、具体的な強化方法を学ぶことを目的として、以下の流れで進行しました。
- 公共システムとクラウドレジリエンスの概要
- レジリエンスライフサイクルフレームワークの詳細
- AWSのマネージドサービスの紹介
- まとめと今後の展望
公共システムとクラウドレジリエンス
公共システムは国民生活を支える重要な社会基盤であり、可用性と性能・拡張性が求められます。クラウドレジリエンスは、障害から迅速に回復する能力を持つシステムを構築するための包括的なアプローチです。

「壊れない」システムから「壊れてもすぐ回復する」システムへと進化することが、現代の公共システムにおいて重要な課題となっています。
レジリエンスの構成要素
レジリエンスとは、アプリケーションがインフラストラクチャ、依存サービス、構成ミス、一時的なネットワークの問題、負荷の急上昇などに起因するシステムの中断に耐えたり、中断から回復する力を指します。

レジリエンスを高めるために重要な要素は以下の通りです。
- 高可用性を意識した運用設計
- ディザスタリカバリ環境
- 継続的なテストと改善
- システム全体にわたるオブザーバビリティの確保
堅牢性とレジリエンスの違い

堅牢性は障害を防ぐ予防的アプローチであるのに対し、レジリエンスは障害から回復する適応的アプローチです。
デジタル社会の進化に伴い、公共システムにおいても稼働中に要件が変化していくケースが増加しています。堅牢性だけでは対応が難しい状況が増え、レジリエンスの重要性はさらに高まっています。
レジリエンスライフサイクルフレームワーク
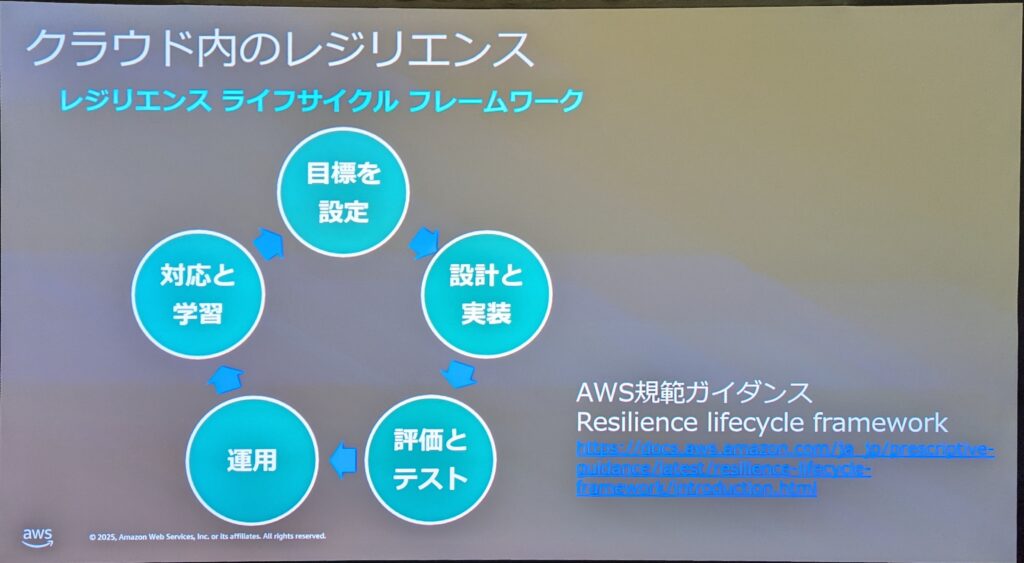
レジリエンスライフサイクルフレームワークとは、AWSが開発したフレームワークで、以下の5つのステージを通じてレジリエンスを向上させます。
1. 目標を設定

必要なレジリエンスのレベルと測定方法を理解し目標を設定します。アプリケーションのどの部分にどの程度のレジリエンスレベルが必要なのか確認し、RTO(目標復旧時間)/RPO(目標復旧時点)/SLO(サービスレベル目標)等の測定可能な目標を設定します。サービスの信頼性と性能に関する測定可能な目標値であるSLOは、利用者の体験に直結するので最も重要です。
2. 設計と実装
設定した目標に従い、システムがどのように障害を起こす可能性があるか理解し、迅速に回復するための技術的方式を決定し実装します。期待されるレジリエンス特性として、タイムリーな実行、正確な実行、障害の分離、十分なキャパシティ、冗長性が挙げられます。ただし、これらを高める際にはコストや複雑性などのトレードオフを考慮する必要があります。
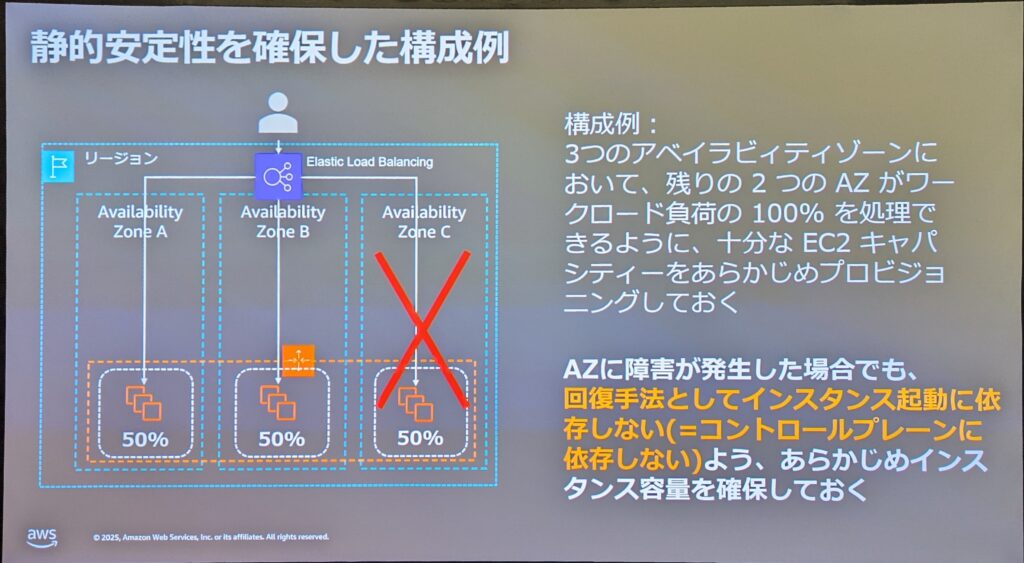
さらに、静的安定性の概念を取り入れることが重要です。静的安定性とは、システムが静的な状態で動作し、依存関係に障害が発生したり利用できなくなったりした場合でも変更を加える必要なく、通常通り動作し続けることができる性質を指します。これにより、ミッションクリティカルな重要業務においても高い可用性を確保することが可能です。
3. 評価とテスト

実装したワークロードをテストし、結果を評価します。カオスエンジニアリングを活用して未知の事象に対応する手法が有効です。AWS Resilience Hub の AWS Fault Injection Serviceを利用して、障害注入を実行し、システムの回復力を検証・改善します。
4. 運用

アプリケーションを本番環境にデプロイし、カスタマーエクスペリエンスを管理します。障害を検出、調査、解決するために収集すべきデータとして、カスタマーエクスペリエンスを測定するメトリクス、影響範囲やその大きさを測定するメトリクス、運用の健全性を測定するメトリクスが挙げられます。

Amazon CloudWatch Syntheticsは、ウェブサイト、API、その他のエンドポイントを監視するためのフルマネージドサービスです。実際のユーザ行動をシミュレートするCanaryと呼ばれる定義を行うことで、アプリケーションの可用性や性能を継続的に検証します。一定間隔でエンドポイントに対してトラフィックを送信する外形監視を構築でき、人間が気づくよりも早い段階で障害を検出することが可能です。
5. 対応と学習
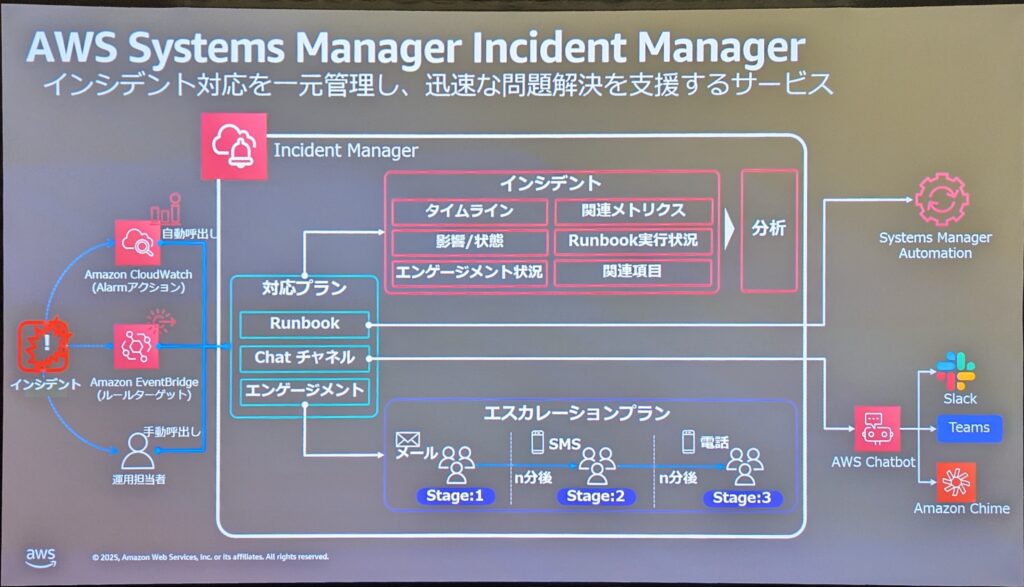
インシデントに適切に対応し、経験から最大量の学習を得ます。インシデント後の分析を通じて、問題の根本原因を特定し、改善策を見つけ、再発防止のためのアクションアイテムを特定・追跡します。AWS Systems Manager Incident Managerを活用して、インシデント対応を一元管理し、継続的な改善を行います。
継続的なレジリエンス確保に向けたアクション
クラウドレジリエンスを継続的に確保するためのサービスが紹介されました。
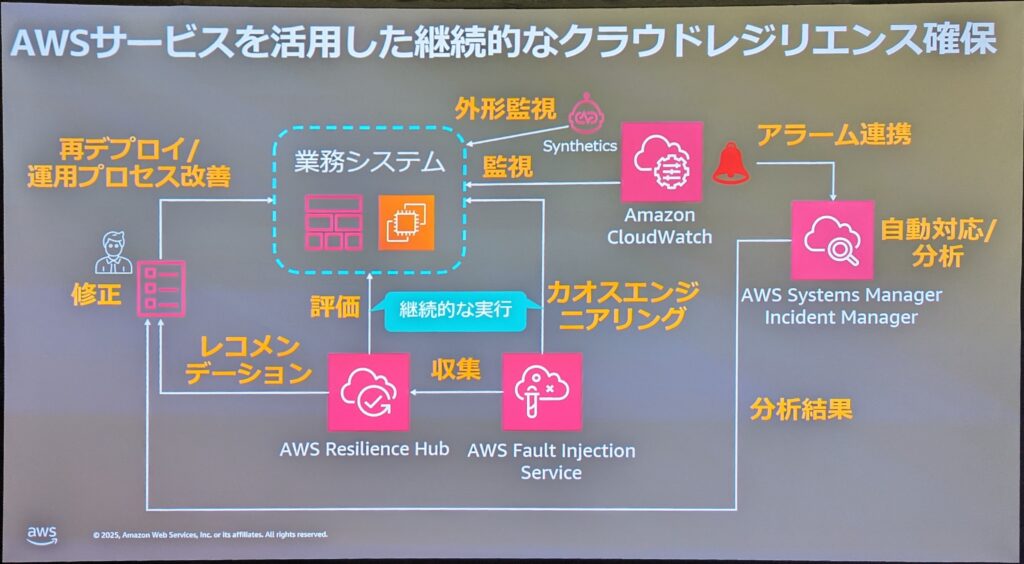
- AWS Fault Injection Service: 障害注入を実行・管理
- Amazon CloudWatch Synthetics: 外形監視を構築し、障害を早期検出
- AWS Systems Manager Incident Manager: インシデント対応を一元管理
- AWS Resilience Hub: 回復力の定義・検証・追跡を一元化
まとめ
クラウドレジリエンスは、公共システムの可用性と性能を向上させるための重要なアプローチです。AWSの提供するフレームワークやサービスを活用することで、障害から迅速に回復し、国民生活への影響を最小限に抑えるシステムを構築することが可能です。
この講演を通じて、公共システムにおけるクラウドレジリエンスの重要性と、AWSが提供する具体的なフレームワークやツールを活用した実現方法を深く理解できました。
特に、「壊れてもすぐ回復する」システムへのパラダイムシフトや、カオスエンジニアリング、静的安定性、オブザーバビリティといった概念は、今後のシステム設計や運用において意識すべきポイントだと感じました。
これらの学びは、公共機関だけでなく、信頼性の高いシステムを求めるあらゆる組織にとって価値のある示唆を提供していると思います。本記事が皆さんの参考になれば幸いです。

