

Bucardoを用いた古いPostgreSQLからAlloyDB for PostgreSQLへの移行方法
はじめに

皆様の中に最新のクラウド型データベースサービスへの移行を行いたいけど、バージョンが古いため移行を断念している方もいらっしゃるのではないでしょうか?
そこで今回は、PostgreSQL9以前のデータベースをBucardoというソフトウェアを用いてGoogle CloudサービスのAlloyDB for PostgreSQLへ移行する方法をご紹介します!
記事前半では利用する機能の概要を、後半では実践例をお伝えするので、是非ご覧ください。
DBaaSについて
PostgreSQLやAlloyDBについて理解を深める上で、前提として理解しておきたいのがDBaaSです。DBaaSは「DataBase as a Service」の略称で、日本語では「サービスとしてのデータベース」という呼称で知られています。
データベースは通常、専用のデータベース管理システム「DBMS」によって管理されているのが一般的です。DBaaSは、そんなDBMSを使ったデータベース管理をより効率的なものとするためのサービスとして、普及が進んでいます。
データベース管理に関する日々のタスクを、DBaaSの導入によって効率化が可能です。手間がかかるだけでなく、時間も必要なタスクが自動化されるため、管理者の業務効率化や、コスト削減において絶大な効果が期待できます。
PostgreSQLの概要
PostgreSQLは、オープンソースで提供されているリレーショナルデータベース管理システム(RDBMS)の一種です。世界で広く採用されている実績があり、それでいて無料であることから、日本でも高い人気を誇ります。
また、オープンソースということもあり拡張性が高く、汎用な使い方ができるため、ベンダーロックインに陥りにくい点も強みの一つです。
オープンソースでありながら、ビジネスにも十分に通用する堅牢性と機能性を備えているので、大規模な運用を考えている場合にも将来性にリスクを抱える心配がありません。
AlloyDB for PostgreSQLの概要

そんなPostgreSQLと合わせて導入されているのが、AlloyDB for PostgreSQLです。
AlloyDB for PostgreSQLとは、Google Cloudが提供するフルマネージド型のデータベースサービスです。
PostgreSQLと互換性を持ちますが、標準的なPostgreSQLとの性能比較テストでは、トランザクション処理で4倍以上、分析クエリで最大100倍の高速化を実現できていることが確認されています。非常にパワフルな性能を有し、業務の効率化に貢献できるサービスです。
さらに、無停止でのインスタンスサイズの変更とデータベースメンテナンスに対応している点も同サービスの特徴です。メンテナンス含め、 99.99%という非常に高い可用性を実現し、抜群の安定感を誇ります。
そのため、従来よりもさらにハイパフォーマンスな環境を求めている場合、例えばPostgreSQLでは要件などの面から役不足であるシーンなどにおいて、高い効果を発揮するでしょう。
AlloyDBの料金システム
AlloyDB for PostgreSQLは、わかりやすい料金システムを整備しているのが特徴です。主な料金の構成要素は、
- CPUとメモリ
- ストレージ
- バックアップストレージ
- ネットワーク
の4つです。それぞれの要素を期間内にどれだけ使ったかによって、最終的な料金が決定します。
特徴的なのは、継続利用期間に応じて一定の割引が行われる点です。1年間の継続利用、3年間の継続利用と継続利用期間に応じて、割引料金が適用されます。使用期間が長くなればなるほど、お得になるのはありがたいメリットです。
また、ネットワーク利用については、別のリージョンへのアウトバウンドトラフィックが発生する場合、お金がかかります。AlloyDB for PostgreSQLへのデータ転送が無料な点は、強みの一つと言えるでしょう。
Bucardoの概要
Bucardoとは、PostgreSQLのレプリケーションを実現するためのオープンソースソフトウェアです。
トリガ―ベースのレプリケーションシステムであり、複数のマスターとセカンダリを対象に非同期でマルチマスターレプリケーションを実現することが可能です。
ただし、プライマリキーのないテーブルに対してはレプリケーションの設定を行えません。
Bucardoを用いて移行を行う理由
続いて、Bucardoを用いて移行する理由についてお伝えします。
PostgreSQL9以前のPostgreSQLではロジカルレプリケーションに対応しておらず、メジャーバージョンのローリングアップデートを行うことが出来ません。そのため、メジャーバージョンのアップデートを行う際はデータベースへの書き込みを停止させて、データベースの移行を行う必要があります。
Bucardoを用いることで、データベースのデータを新環境に移行している間の更新も保持して、移行先に反映することができるためより少ないダウンタイムでデータベースの移行を実現することが可能です。
PostgreSQL9.2のDBからAlloyDBへの移行の流れ
下記のような手順で移行していきます。
1. AlloyDBとAlloyDB操作用兼、Bucardo用のGCEインスタンスの作成
AlloyDBのクラスタとプライマリインスタンスの作成とAlloyDBを操作するためとBucardoを動作させるためのGCEインスタンスを作成します。
2. AlloyDBの前作業
Bucardoのレプリケーションを行うために先にスキーマが必要なため、ユーザとデータベースを作成して、データベースにスキーマのみ事前に反映しておきます。
3. Bucardoのインストール
Bucardoが設定や変更を保持するためのデータベースの作成を行い、Bucardoを利用できる状態にしておきます。
4. Bucardoのセットアップ
Bucardoにレプリケーションを行うサーバの登録や、テーブルとシーケンスなど同期に必要な情報をBucardoに登録します。
5. Bucardoの同期を開始
データ移行中の変更を保持するためにBucardoの同期を開始します。
6. 旧DBからAlloyDBへデータの移行
pg_dumpとpg_restoreを用いたデータの移行を行います。
7. Bucardoの同期を反映
データ移行中の変更と今後のデータの変更をAlloyDBに反映するためにレプリケーションの同期を開始します。
8. データベースの参照先を変更
データの更新をAlloyDBにのみ書き込みを行えるよう変更します。
9. Bucardoの停止
レプリケーションを停止して旧DBとの同期を切り離します。
10. 移行完了
検証環境の準備
それでは検証環境の作成から実践していきましょう。
1. AlloyDBとAlloyDB操作用兼Bucardo用のGCEインスタンスの作成
AlloyDBのクラスタとプライマリインスタンスを作成します。今回は、検証のため最小構成で作成します。
まずGoogle Cloud Consoleを開き、Compute Engine APIを有効にします。

次に、Service Networking APIを有効にします。
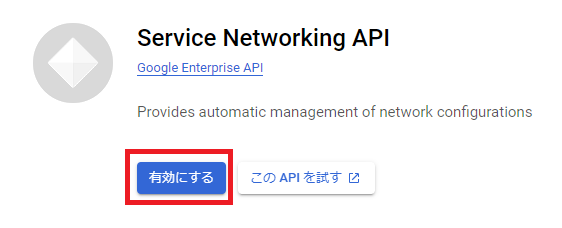
続いてAlloyDB APIを有効にし、「クラスタを作成」をクリックします。

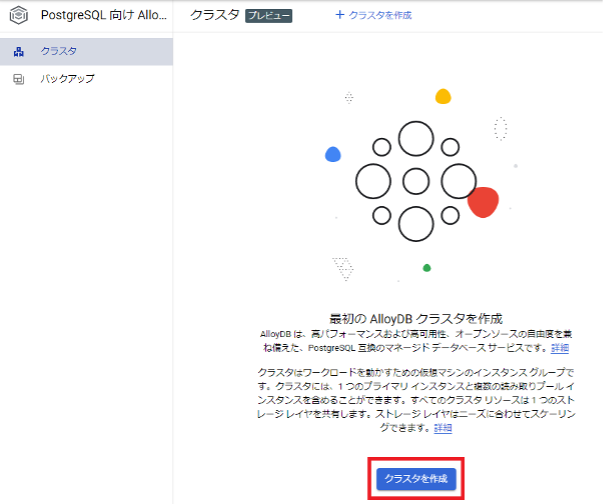
ここではクラスタタイプの選択します。
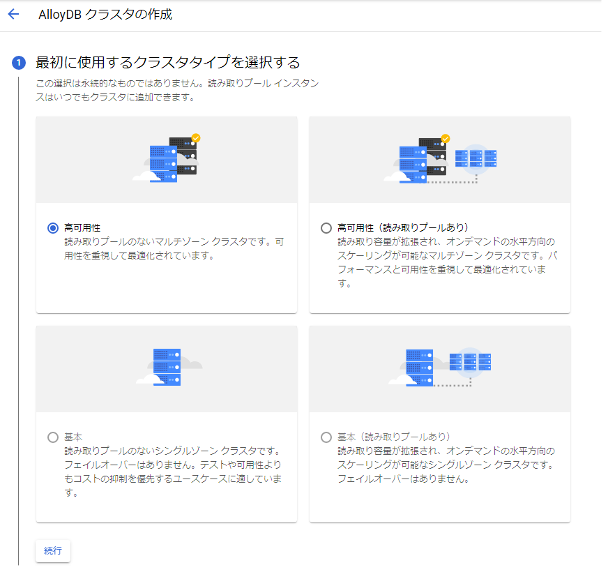
クラスタを構成するこの画面では、後続で作成するGCEが接続できるようなネットワークを利用してください。
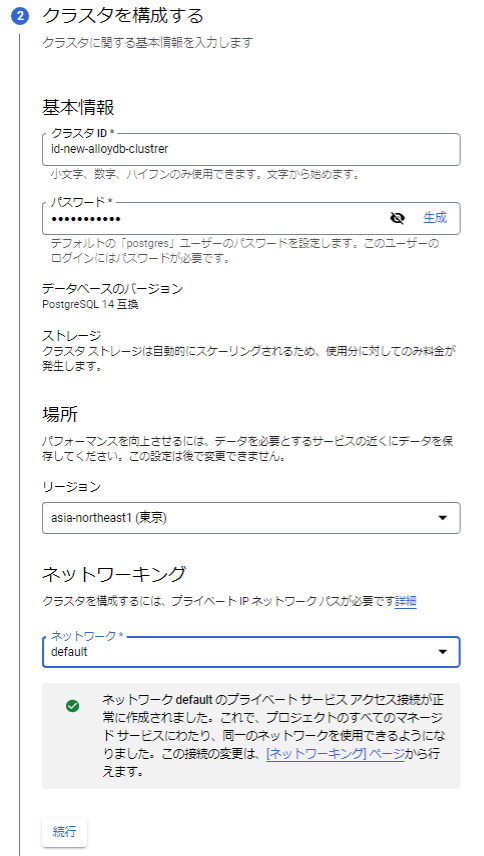
続いてプライマリインスタンスの構成をします。今回の検証では大きなデータを利用しないため、最小構成のもので作成を行いました。
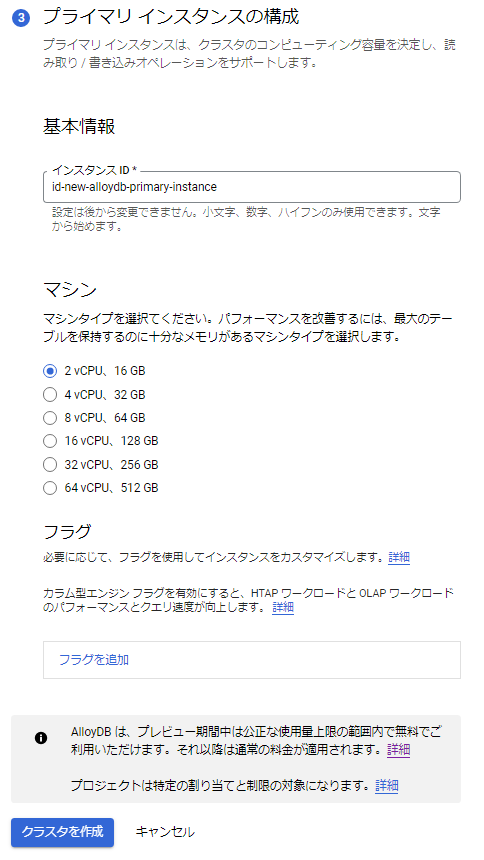
ここで、作成したAlloyDBのプライベートアドレスを確認します。(以下、$Alloy_IPとする)以上で、AlloyDBとAlloyDB操作用兼Bucardo用のGCEインスタンスの作成は完了です。
AlloyDB操作兼Bucardo用GCEインスタンス(以下、bucardo-vm)を作成
今回はネットワークの設定を簡単にして検証を行うためにAlloyDBと同じプロジェクトとVPC上で作成しております。
利用OSはCentOS8 Streamとし、内部IPを$bucardo_IPとします。
移行対象のpostgresql9.2のデータベース用GCEインスタンス(以下、old-db-vm)を作成
今回はネットワークの設定を簡単にして検証を行うためにAlloyDBと同じプロジェクトとVPC上で作成しております。利用したOSはCentOS7、内部IPは$old_db_IP、操作はold-db-vm上で行います。
まず、テスト用DBの作成のために下記をインストールします。
sudo yum -y install postgresql-server postgresql-contribインストールは、以下で行います。
yum list installed | grep postgresql自環境での実行結果は、このようになりました。

続いて、クラスタを作成します。
su – postgres
initdb
exitbucardo-vmから、操作の許可を行うために下記を修正しておきます。
続いて、PostgreSQLのサービスを起動します。
sudo systemctl start postgresql.serviceユーザーとデータベースを作成します。(以下、旧DBとします。)
createuser -s db_user -U postgres
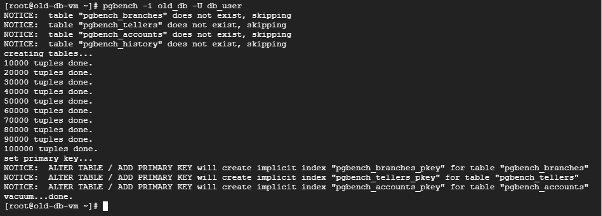
createdb old_db -U db_user検証用データを作成します。
pgbench -i old_db -U db_user自環境での実行結果は、このようになりました。
PostgreSQL 9.2のDBからAlloyDBへの移行方法
2. AlloyDBの前作業
AlloyDBの前作業は、Bucardo-vm上で行います。
まずは、Postgresqlサービスを起動させてPostgresqlをインストールしましょう。
sudo dnf install postgresql-server postgresql-contrib以下を使用して、インストールの確認を行います。
dnf list --installed | grep postgresql
上記で強制終了されてしまう場合、下記を実行しておきます。
sudo dnf config-manager --disable google-cloud-sdk続いて、データベースのユーザーを作成します。まずは、AlloyDBにpsqlを用いてpostgresユーザで接続します。
psql -h $Alloy_IP -U postgres postgres次に、ユーザーの作成の作成を行います。ここでは、ユーザ名を「db_user」とします。Created, Replication, loginの権限とパスワードを設定しましょう。
CREATE USER db_user WITH created Replication login password pass_db_user';次に、db_userでデータベースの作成を行います。まずは、AlloyDBにpsqlを用いてdb_userユーザで接続しましょう。
psql -h $Alloy_IP -U db_user postgres続いて、作成したデータベースへの接続時にパスワードを省略するために、.pgpassを作成します。まずは、pgpassファイルを作り「$Alloy_IP:5432:new_db:db_user:pass_db_user」を書き込みます。
vi .pgpass
chmod 600 .pgpassパスワードの入力無しでログインできることを確認します。
psql -h $Alloy_IP -U db_user new_db次に、旧DBのスキーマを取得します。オプションの「–schema-only」はスキーマのみダンプを行うもの、「–no-privileges 」はアクセス権限(grant/revokeコマンド)のダンプを抑制するもの、「–schema」は指定したスキーマのみダンプを行うためのものです。
pg_dump -v \
-h $old_db_IP \
-U db_user --schema-only \
--no-privileges --schema=public old_db \
--file=old_db_schema.sql次に、AlloyDBへ旧DBのスキーマを反映します。
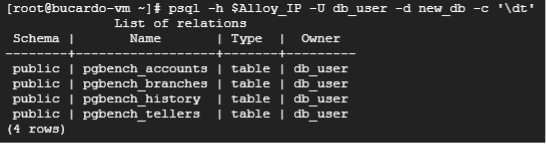
psql -h $Alloy_IP -U db_user -d new_db -f old_db_schema.sql旧DBのスキーマを反映されたかどうか、以下で確認します。
psql -h $Alloy_IP -U db_user -d new_db -c '\dt'自環境での実行結果は、以下の通りになりました。
3. Bucardoのインストール
Bucardoのインストールは、bucardo-vm上で行います。まずは、Bucardoの動作に必要なパッケージのインストールしましょう。
sudo dnf install -y epel-release
sudo dnf install -y bucardo perl-open perl-DBI perl-Time-HiRes perl-DBD-Pg perl-DBIx-Safe postgresql-plperl perl-Sys-Syslog perl-Pod-Parser続いて、データベースクラスタを作成します。
sudo su – postgres
initdb
exit次に、old-db-vmからの操作を許可するための修正しておきます。(例:pg_hba.conf, postgresql.confなど)修正後、PostgreSQLのサービスを起動します。
sudo systemctl start postgresql.service次に、Bucardo用のユーザとデータベースを作成します。
createuser -U postgres -s bucardo
createdb -U bucardo -E UTF8 bucardo次に、Bucardoのインストールし、Bucardoを確認します。
bucardo --version自環境での実行結果は、以下の通りです。
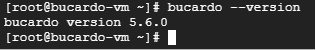
続いて、必要なディレクトリの作成します。
mkdir /var/run/bucardo
mkdir /var/log/bucardo次にbucardoデータベースに反映します。
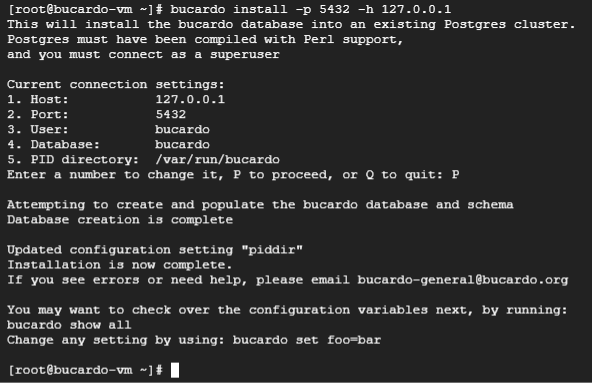
bucardo install -p 5432 -h 127.0.0.1自環境での実行結果は、以下の通りです。
4. Bucardoのセットアップ
この作業は、bucardo-vm上で行います。まずは、旧DBに移行元のDBを登録します。(旧DB)
bucardo add db old_db dbhost=$old_db_IP dbport=5432 \
dbname=old_db dbuser=db_user自環境での実行結果はこのようになりました。
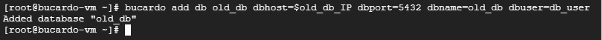
続いて、移行先のDBを登録します。(AlloyDB)
bucardo add db new_db dbhost=$Alloy_IP dbport=5432 \
dbname=new_db dbuser=db_user dbpass=pass_db_user自環境での実行結果はこのようになります。

次に、レプリケートを行うテーブルを登録します。
bucardo add all tables --exclude-table pgbench_history \
--db=old_db --herd=my_herd --verbose自環境での実行結果はこのようになります。「exclude-table」は、レプリケートを行わないテーブルを追加するためのオプションです。

続いて、レプリケートを行うシーケンスを登録します。今回の実践ではシーケンスが存在しないため実行しませんが、テーブル同様の登録方法で実行します。以下は例です。
bucardo add all sequences --db=old_db --herd=my_herd --verbose次に、レプリケートを行うテーブルグループを登録します。今回はマルチマスタレプリケーション形式を利用します。オプションの「source」はマスターとなるDBを指定、「target」はレプリケート先のDBを指定するためのものです。
bucardo add dbgroup my_dbs old_db:source new_db:source自環境での実行結果はこのようになります。

続いて、同期の登録を行います、オプションの「autokick」は同期の反映を自動的に行うかの設定(0: オフ, 1: オン)ができます。
bucardo add sync sync_my_dbs relgroup=my_herd dbs=my_dbs autokick=0自環境での実行結果はこのようになります。
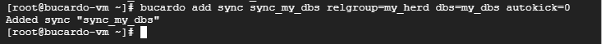
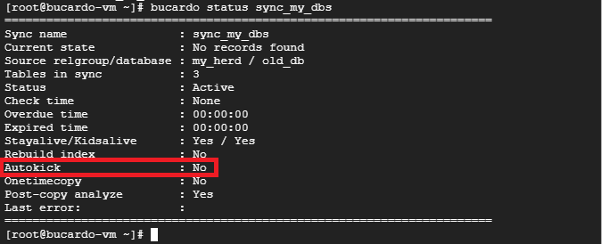
ここで、自動同期がオフになっていることを確認します。
bucardo status sync_my_dbs自環境での実行結果はこのようになりました。
最後に、設定が正しく行われていることを検証します。
bucardo validate all自環境での実行結果は、このようになりました。

5. Bucardoの同期を開始
Bucardoの同期は、bucardo-vm上で行います。以下を用いて同期を開始します。
sudo bucardo --loglevel=debug start自環境での実行結果はこのようになります。 /var/log/bucardo/log.bucardoに、ログが出力されている事が分かりました。

6. 旧DBからAlloyDBへデータの移行
この作業は、bucardo-vm上で行います。まずは、1つ目の検証のためにbucardoのデルタを確認します。
bucardo delta自環境での実行結果はこのようになります。
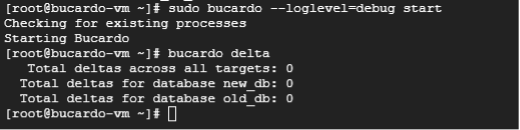
続いて、旧DBのデータを取得します。この際、オプションの「Fc: pg_restore」にあった形式でダンプを行います。「blobs:」は ラージオブジェクトもダンプに含んでおり、「N」はダンプしないスキーマを指定できます。
pg_dump -v -h $old_db_IP -U db_user \
--file=old_data.sql -Fc \
--no-privileges --schema=public --blobs \
-N bucardo old_db続いて、2つ目の検証のために旧DBにレコードを登録します。
psql -h $old_db_IP old_db -U db_user \
-c "INSERT INTO pgbench_branches VALUES (2, 1, 'test2-1');"Bucardo deltaを確認します。
bucardo delta自環境の実行結果は、このようになりました。

次に、旧DBのレコードをAlloyDBへ反映します。オプションの「data-only」はデータのみをリストアします。「disable-triggers」はリストア中のトリガを無効化するものです。
pg_restore -v -h $Alloy_IP -U db_user \
--data-only --disable-triggers -d new_db old_data.sql3つ目の検証のため、旧DBにレコードを登録します。
psql -h $old_db_IP old_db -U db_user \
-c "INSERT INTO pgbench_branches VALUES (3, 2, 'test3-2');"Bucardo deltaの確認をします。

続いて、Bucardo deltaの確認を行い、まずnew_dbの値が0であることを確認します。その後、4つ目の検証のために、旧DBとAlloyDBのテーブル「pgbench_branches」のレコード数を取得します。
psql -h $old_db_IP old_db -U db_user -c "SELECT COUNT(bid) FROM pgbench_branches;"
psql -h $Alloy_IP new_db -U db_user -c "SELECT COUNT(bid) FROM pgbench_branches;"レコード数がold_db は3、newdbは1であること確認したら、旧DBからAlloyDBへデータの移行は完了です。

7. Bucardoの同期を反映
Bucardoの同期を反映するため、まずは同期を自動実行に変更します。
bucardo update sync sync_my_dbs autokick=1
bucardo reload以下で、自動実行に変更されていることを確認します。
bucardo status sync_my_dbsその後、autokickがYesになっていることを確認してください。
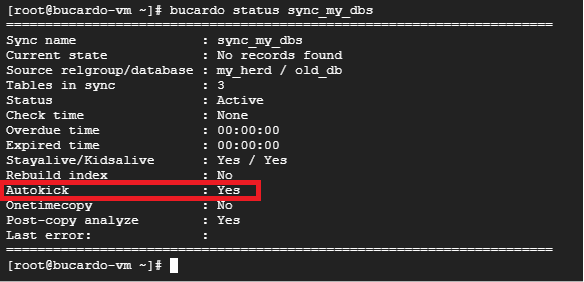
続いて、レプリケーションが行われていることを確認します。
psql -h $old_db_IP old_db -U db_user -c "SELECT COUNT(bid) FROM pgbench_branches;"
psql -h $Alloy_IP new_db -U db_user -c "SELECT COUNT(bid) FROM pgbench_branches;"これで、等しい値が取得できていることが確認できます。
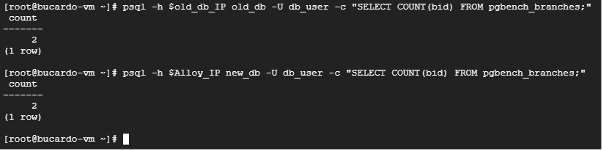
次に、4つ目の検証のためAlloyDBにレコードを登録します。
psql -h $Alloy_IP new_db -U db_user \ -c "INSERT INTO pgbench_accounts (aid, bid) VALUES (100001, 2);"その後、マルチマスタレプリケーション構成になっていることを確認します。
psql -h $old_db_IP old_db -U db_user \
-c "SELECT COUNT(bid) FROM pgbench_accounts;"
psql -h $Alloy_IP new_db -U db_user \
-c "SELECT COUNT(bid) FROM pgbench_accounts;"これで、等しい値が取得できていることを確認できました。
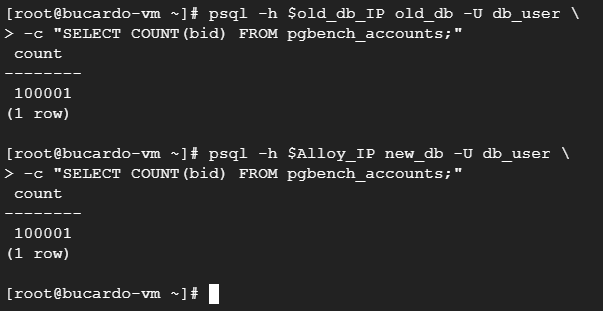
8. データベースの参照先を変更
今回の実践では行いませんが、旧DBへの書き込みを停止してWebサービスなどのDB参照をここで切り替えます。
9. Bucardoの停止
Bucardoの停止の際は、データベースの更新内容を反映しないようにします。
bucardo deactivate sync_my_dbs自環境で実行すると、以下のようになります。

続いて、反映を確認します。
bucardo status sync_my_dbs自環境での実行結果は、このようになります。
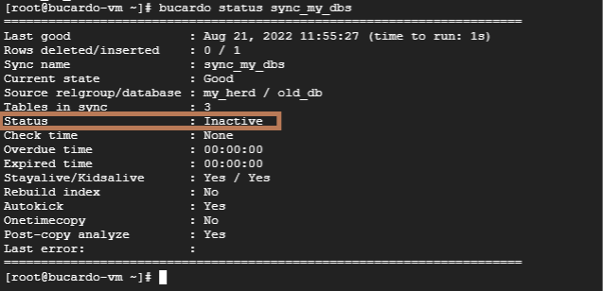
次に、Bucardoを停止します。
bucardo stop実行結果はこのようになります。

次に、各DB上でBucardo作成時に追加されたスキーマとトリガを削除します。
psql -h $old_db_IP old_db -U db_user \
-c "DROP SCHEMA bucardo CASCADE;"
psql -h $Alloy_IP new_db -U db_user \
-c "DROP SCHEMA bucardo CASCADE;"Bucardo用データベースとユーザの削除を行います。
dropdb bucardo -U bucardo
dropuser bucardo -U postgresBucardo用フォルダの削除したら、移行は完了です。
sudo rm -rf /var/log/bucardo
sudo rm -rf /var/run/bucardoまとめ

今回は、AlloyDBとBucardoの概要説明とPostgresql9をAlloyDBへ移行する方法をご紹介しました。AlloyDBはうまく運用できれば、業務の効率化やコストパフォーマンスの改善において、大きな効果を発揮します。
また、後半ではその実践方法を記述しました。今回の方法はストリーミングレプリケーションを実施しており、レコードの取得時間が長いデータベースを対象にした少ないダウンタイムでの実施を目標にした手順での簡易な実践にとどまっています。。
今回のポイントは、単純なデータベース構成でデータの量が非常に少なく、常に書き込みが行われている訳ではない検証環境での実施だった点です。そのため、実際の環境において手続きを実施する場合、より念密な実行計画作成と検証を行う必要があることにご注意ください。
最後までお読みいただきありがとうございました。
