

AWSの障害履歴から考える システム信頼性の高い設計とは?

過去に発生したAWS障害の情報は、AWSのマネジメントコンソールや障害の概要をまとめた公式ドキュメントなどから確認できます。
この記事には、AWSの障害履歴を確認する方法と、過去のAWS障害から考えられる信頼性に関する設計の参考になる情報を記載します。
AWS障害履歴の確認方法
AWSの障害履歴を確認する方法を3つの分類に分けて記載します。
大きくは、AWS Health Dashboardから確認する方法と、AWS Post-Event Summaryの2つを記載し、AWS Health Dashboardについては、アカウント固有のイベント履歴を表示するイベントログ画面とパブリックな障害履歴を表示するステータス履歴画面の2つを記載します。
AWS Health Dashboardのイベントログ画面から確認する
AWS Health Dashboardのイベントログ画面では、アカウント固有のイベントの履歴を確認できます。
AWS Healthサービスにおいて、アカウント固有のイベントとは、利用しているAWSリソースに影響するイベントとされています。
例えば、特定のAWSリージョンで障害が発生した際に、一部のEC2インスタンスに影響がある場合は、影響のあるEC2インスタンスとひもづくAWSアカウントの利用者にのみ情報が表示されます。
ただし、アカウント固有のイベントを表示するとされているAWS Health Dashboardのアカウントの状態メニューの各画面には、アカウント固有のイベント以外に、広い範囲に影響するパブリックな障害情報も掲載されます。これは、障害の影響範囲が未確定の場合でも、影響する可能性のある利用者に情報を伝えるための仕様であると考えられます。
イベントログの画面には、過去90日間のアカウント固有のイベントが表示されます。
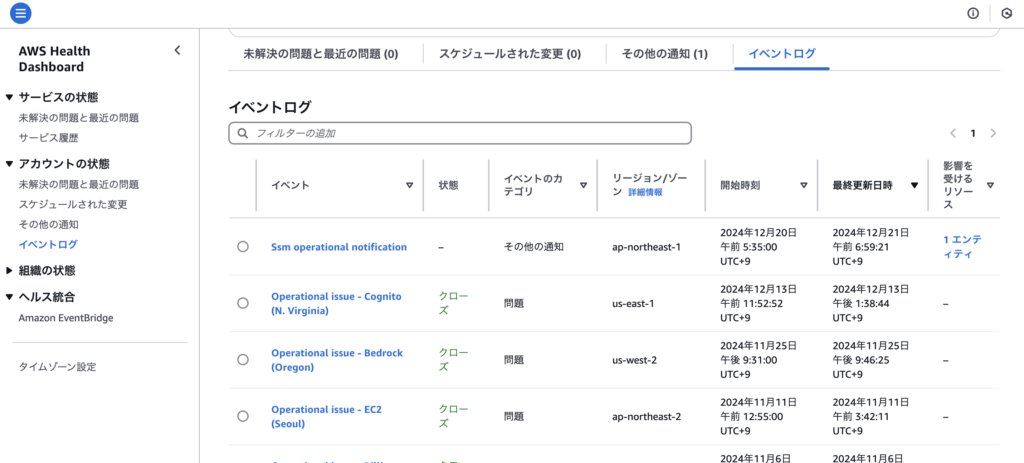
なお、イベントログ画面には、AWS障害に関する情報以外に、AWSサービスのメンテナンス予定やアクションが必要な計画されたライフサイクルイベントと呼ばれる情報も表示されます。
AWS Health Dashboardのステータス履歴画面から確認する
AWS Health Dashboardのステータス履歴画面では、パブリックイベントの履歴を確認できます。
AWS Healthサービスにおいて、パブリックイベントとは、利用しているAWSリソースに関係なく、AWSサービスの障害や重要な不具合が発生した際に共有される情報を指します。
例えば、オハイオリージョン(us-east-2)のAmazon Simple Storage Service(S3)に問題が発生した際、利用者がオハイオリージョンにS3バケットを作成していなくてもイベント情報が表示されます。
イベント一覧を選択すると、イベントの一覧が表示され、サービス一覧を選択すると、AWSサービスとリージョンごとの現在の正常性を示すアイコンが表示されます。
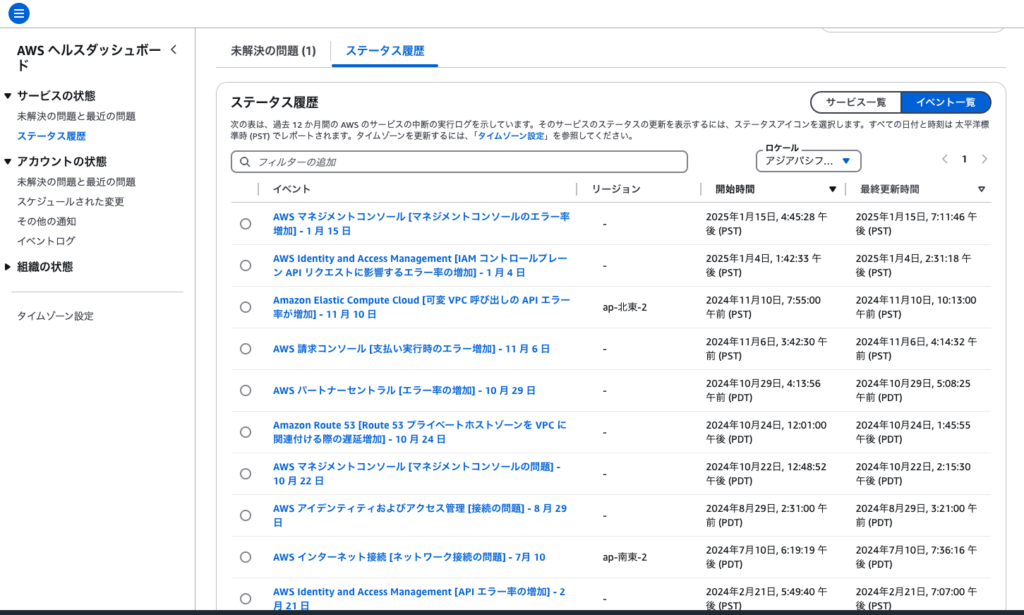
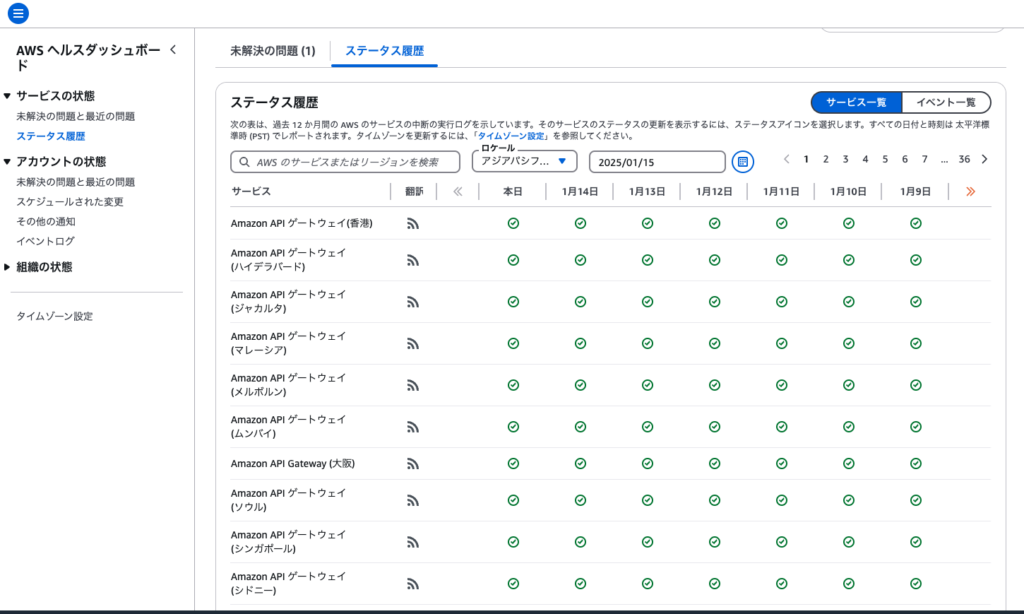
なお、イベント一覧には、過去12カ月間のパブリックイベントが表示されます。
AWS Post-Event Summaryから確認する
AWS障害によって、利用者に広範囲で重大な影響を及ぼした場合、問題の解決後にPost-Event Summaryを公開することが約束されています。
Post-Event Summaryは、最低5年間公開され、問題の影響範囲、問題の原因となった要因、特定されたリスクに対処するために取られた措置が記載されます。

例えば、北バージニアリージョン(US-EAST-1)で発生したAmazon Kinesis障害についての情報は、このように公開されています。

過去のAWS障害事例とWell-Architectedフレームワークから考えるシステム信頼性に関する設計
AWSを用いたシステム構築の設計に役立つ情報として、Well-Architectedフレームワークという公式ドキュメントが公開されています。
以下に、Post-Event Summaryで報告されているいくつかの過去の障害事例を持ち出し、Well-Architectedフレームワーク6つの柱のうち、障害と関連性の高い信頼性の柱のセクションに記載されている情報を引用します。
東京リージョン(AP-NORTHEAST-1)で発生したAWS Direct Connect障害の事例
2021年9月2日午前7時30分(日本時間)頃から6時間にかけて、AWS東京リージョンと接続するDirect Connectサービスが中断する事象が発生しました。
この事象は、AWSと接続するデータセンターなどとAWSの中継をするDirect Connectロケーションから、利用者のVirtual Private Cloud(VPC)が存在する東京リージョンのデータセンターネットワークへの接続を担う一部のネットワークデバイスに障害が発生したことが原因とされています。
AWSが公表する情報からすると、以下の図のPrivate Virtual Interface(VIF)からDX-GWにVirtual Private Gateways(VGWs)向かう緑色の経路または、Transit Virtual Interface(VIF)からDX-GWに向かうオレンジ色の経路上で障害が発生したと考えられます。
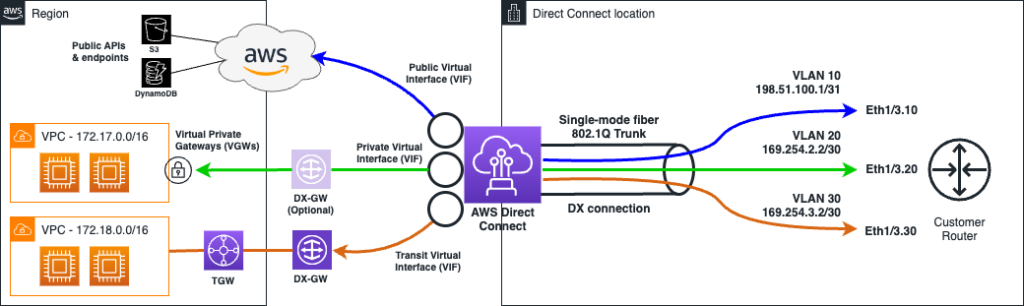
この障害によって、Direct Connectを用いてAWSのVPCと利用者が管理するデータセンター間の通信に問題が生じ、例えば利用者が管理するオンプレミス環境のサーバーとAWSのVPC上のEC2やRDSなどのリソース間に必要な通信ができなくなったことで、AWSまたは利用者が管理するデータセンター上のデータベースやAPIに接続できなくなることが考えられます。
データベースはAWSのRDSを使用し、APIやWebサーバーは利用者が管理するデータセンター上に設置し、Direct Connectを用いて双方の通信を中継する構成のWebサイトがあった場合、Direct Connectの障害によってWebサイトが利用不可になるという影響が発生し得ます。
この障害において、AWS Virtual Private Network(VPN)を使用している利用者には影響がなかったとAWSは報告しています。
AWS VPNには、主にリモートワーカーのパソコンから接続するためのAWS Client VPNとオンプレミスデータセンターなどの利用者が管理する拠点とAWS間を常時接続するSite-to-Site VPNの2つがあります。
Well-Architectedフレームワーク 信頼性の柱の「REL02-BP02 クラウド環境とオンプレミス環境のプライベートネットワーク間の冗長接続をプロビジョニングする」では、Direct Connect接続のバックアップとして、Site-to-Site VPNを利用することを提案しています。
Site-to-Site VPNでは、以下の図のように、利用者が管理するデータセンターなどの拠点とAWS側のTransit GatewayやVirtual Private Gatewayと直接接続します。
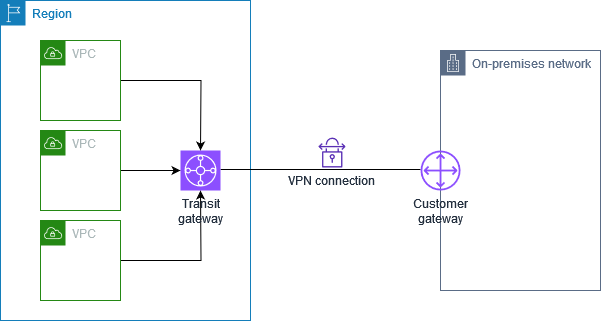
Direct Connectでは、AWSと接続するデータセンターなどとAWSの中継をするDirect Connectロケーションを介するなど、Site-to-Site VPNとは接続の経路が異なります。
Direct Connectの場合も、Site-to-Site VPNの場合も、AWS側でTrangit GatewayやVirtual Private Gateways(VGWs)を利用することは共通していますが、AWSのVPNを使用している利用者には影響がなかったとの報告から、それらのゲートウェイよりもDirect Connectロケーションに近いポイントに障害が発生したと考えられます。
AWSがDirect Connect接続のバックアップとして、Site-to-Site VPNを利用することを提案する理由として、経路の違うサービスを用いることで、障害発生時に冗長化された経路の全てが使用不可になる確率を小さくする狙いがあると考えられます。
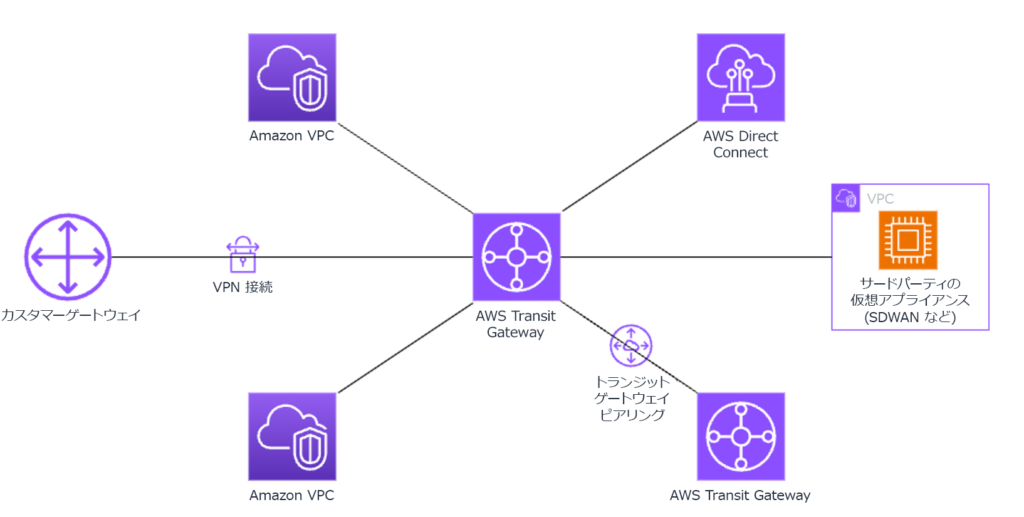
また、Well-Architectedフレームワーク 信頼性の柱の「REL02-BP04 多対多メッシュよりもハブアンドスポークトポロジを優先する」では、Transit Gatewayを用いることで信頼性を高める方法を提案しています。
AWSとオンプレミスデータセンターをDirect Connectを用いて接続し、そのデータセンターからさらに別のクラウドサービスに接続する構成をとっていた場合、Direct Connectの障害によって、AWSとデータセンター、AWSと別のクラウドサービス間の両方の通信に影響が及びますが、Transit Gatewayを用いてAWSとデータセンター、AWSと別のクラウドサービスを直接接続することで、障害の影響範囲をAWSとデータセンター間の通信のみに限定することが狙えます。
東京リージョン(AP-NORTHEAST-1)で発生したAmazon EC2とAmazon EBS障害の事例
2019年8月23日午後0時半頃から6時間にかけて、AWS東京リージョンの1つのアベイラビリティゾーンにて、EC2サーバーの停止やEBSボリュームのパフォーマンスが劣化する事象が発生しました。
この事象は、アベイラビリティゾーンの空調設備の障害により、ハードウェアがオーバーヒートしたことが原因とされています。
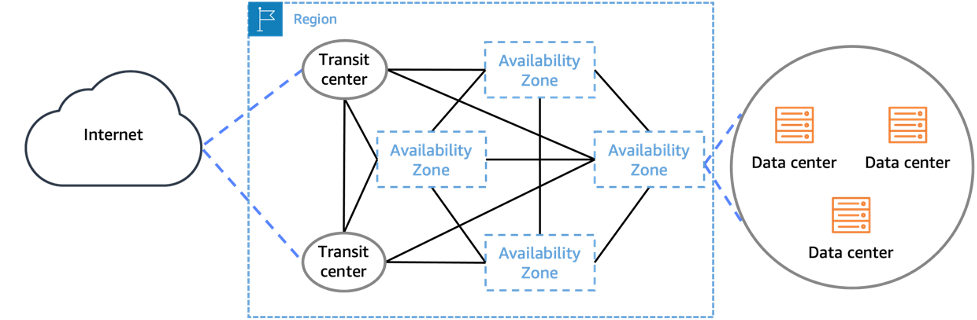
アベイラビリティゾーンとは、AWSのリージョン内のサービスの信頼性を高めるために設計された、同じ機能を持った複数のゾーンのうちの1つを指します。同時に機能停止に陥らないように、各アベイラビリティゾーン間には100km程度の距離が空けられ、1つのアベイラビリティゾーンは1つ以上のデータセンターで構成されています。
この障害によって、オーバーヒートが発生したアベイラビリティゾーンで稼働していたEC2インスタンスのうち一部が停止したり、EBSを用いたシステムの応答時間の遅延が発生したと考えられます。なお、AWS RDSはストレージとしてEBSを使用しているとされており、この障害によってRDSの動作にも影響があったこともAWSから公表されています。
また、この障害では、複数のアベイラビリティゾーンでEC2などを稼働していた利用者のアプリケーションにも、予期せぬ影響があったとAWSは報告しています。Application Load Balancer(ALB)に組み合わせている設定によっては、リクエストに対してエラーを返す割合が増加したとのことでした。
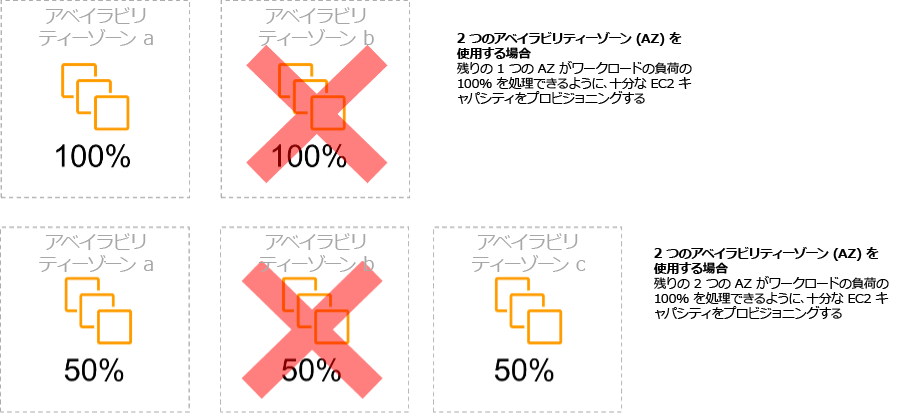
Well-Architectedフレームワーク 信頼性の柱の「REL10-BP01 複数の場所にワークロードをデプロイする」では、耐障害性と高可用性の実現のために複数のアベイラビリティゾーンまたはリージョンにワークロードを分散することを提案しています。
複数のアベイラビリティゾーンまたはリージョンにワークロードを分散する狙いとしては、特定のアベイラビリティゾーンまたはリージョンに障害が発生したとしても、別のアベイラビリティゾーンまたはリージョンにあらかじめ配置していたワークロードリソースを用いてシステムの動作を継続させることだと考えられます。
ALBに追加する設定次第では、複数のアベイラビリティゾーンにEC2などのワークロードリソースを配置していた場合もこの障害による影響を受けた可能性がありますが、単一のアベイラビリティゾーンにEC2を配置していた場合に比べると影響を受ける確率は低くなると言えます。
Well-Architectedフレームワーク 信頼性の柱の「REL11-BP05 静的安定性を使用してバイモーダル動作を防止する」では、障害発生時に正常なアベイラビリティゾーンにワークロードリソースを起動することは望ましくなく、あらかじめ複数のアベイラビリティゾーンにワークロードリソースを配置しておくことが望ましいとしています。
その理由の明確な説明は見つけることができていませんが、リソースの作成などを行うコントロールプレーンと定義される機構は、EC2インスタンス自体やEBSボリュームの読み取りと書き込みといったサービスの主な機能を提供するデータプレーンに比べて複雑な構造になっていることがあると考えられます。
2019年8月23日に発生した東京リージョンの特定アベイラビリティゾーンで発生した障害によって、他のアベイラビリティゾーンでの同事象の発生は明記されていないものの、Auto Scalingグループからのインスタンスの新規起動への影響が公表されており、AWS障害の多くはコントロールプレーンの機能に影響が出ているようです。
Well-Architectedフレームワーク 信頼性の柱の「REL11-BP04 復旧中はコントロールプレーンではなくデータプレーンを利用する」においても、障害の影響を受けたコンポーネントの交換をコントロールプレーンのスケーリング操作に依存するのではなく、データプレーンの機能を使用した自動的なリカバリおよびフェイルオーバーができる設計を提案しています。
バージニア北部リージョン(US-EAST-1)で発生したAmazon Kinesis障害の事例
2020年11月25日午前5時15分(現地時間)頃から17時間にかけて、Amazon Kinesisのフロントエンド機能へのサーバー追加をトリガーとして、複数のAWSサービスでエラーやレイテンシが増加する事象が発生しました。
この事象は、Kinesisのフロントエンド機能を構成するサーバー内のスレッド数がOSの上限値に達したことが原因とされています。Kinesisのフロントエンド機能は、同目的の他のサーバーと通信するために、フロントエンド機能を構成するサーバー数に比例する数のスレッドをサーバー上に生成するとの解説があります。
現在では、Amazon Kinesisを関するサービスは、基本的なストリーム処理を行うAmazon Kinesis Data Streamsと動画のストリーム配信に特化したAmazon Kinesis Video Streamsの2つしかありませんが、2020年11月当時は、S3などのマネージドサービスへの配信をシンプルに行うData FirehoseやストリームデータをSQLクエリによってリアルタイムに分析するData Analyticsといったサービスもありました。
この障害によって、Amazon Cognito、CloudWatch、CloudWatchに依存するAutoScaling機能、EventBridge、Lambdaサービスに影響が出たことが報告されています。
CloudWatchは、メトリクスやログデータの処理にKinesis Data Streamsを使用しており、CloudWathcメトリクスを使用するAWSサービスに影響が及んだという形のようです。Amazon Cognitoは、Kinesis Data Streamsを用いて利用傾向を収集しており、Kinesis Data Streamsの障害発生によりバッファリングデータがたまり、バッファリング関連のバグが引き起こされ、Cognitoのエラーやレイテンシの増加につながったとされています。
ここでも、東京リージョンで発生したAmazon EC2とAmazon EBS障害の事例と同じWell-Architectedのフレームワークに当てはめて、信頼性に関する設計を考えることができます。
CloudWathcメトリクスを用いて、スケールアウトの判断をするAutoScaling機能が動作しない場合、EC2インスタンスなどのワークロードリソースをCPU使用率などのメトリクスの上昇に応じてスケールアウトできません。
Well-Architectedフレームワーク 信頼性の柱の「REL11-BP05 静的安定性を使用してバイモーダル動作を防止する」では、AWSの障害発生時に焦点を当てて、あらかじめ十分なリソースを稼働させておくことが提案されていますが、AWSの障害とアクセス増などによるワークロードへの負荷増加が重なった場合も同じことが言えなくもありません。
まとめ
ここまで、AWSの障害履歴を確認する方法と、いくつかの過去の障害事例とAWSが提案する構成をWell-Architectedフレームワーク 信頼の柱から引用しました。
AWSの障害履歴から障害の傾向や影響範囲を把握し、システム信頼性に関する設計の参考になれば幸いです。
