

Google App Engine(GAE)で作成したサービスのアクセスエラー率を可視化・アラート通知する方法
はじめに

サーバーレスでアプリケーション開発に集中できる仕組みが整っているGoogle App Engine(以下、GAE)です。ただ、利用に際しては実際にサービスインしたいけど「適切な監視方法が応答監視ぐらいしか思いつかない」「もう少し詳細な監視をしたい」とお悩みの方も多くいらっしゃるのではないでしょうか。
そこで今回は、Cloud Monitoring(以下、Monitoring)を利用した可視化の方法や、実際の監視方法について解説します。
記事前半ではダッシュボードで可視化する方法を、後半ではアラート通知する方法をお伝えするので、是非じっくりとご覧ください。
Google App Engine(GAE)とは
GAEは、Googleが提供するGoogle Cloudのサーバーレスサービスのひとつです。クラウド環境で動作するサービスのため、自社で運用管理の負担に対応する必要はありません。
GAEは、多様なプログラミング言語に対応している点が評価されています。JavaやPython、Node.jsなど、好きな言語で作成したWebアプリケーションをGoogleが管理するサーバーに簡単にデプロイできるPaaS系のプラットフォームです。
GAEは、スケーラビリティに優れているPaaSとして知られます。運用しているサービスの規模が大きくなったり、需要が高まりアクセスが集中すると、通常は負荷が大きくパフォーマンスに影響が出る懸念があります。GAEの場合、サーバーにどれくらい負荷がかかっているかをGoogleサーバー側で自動で判断し、最適なリソースを確保できるのがポイントです。手動対応の際、サーバーを分散するためのロードバランサーの用意が必要になりますが、GAEならこのような負担から解放されます。
GAEにはスタンダード環境とフレキシブル環境の2つの環境が次のような特徴があります。
1. スタンダード環境
スタンダード環境の場合、GAEは以下のような強みを発揮するのが特徴です。
GAEが用意するサンドボックス内で実行される
無料または低コストでアプリケーション開発ができる
インスタンスの稼働時間で課金が発生
スタンダード環境では、GAEが用意するサンドボックス内で処理が行われます。そのため運用に際してかかるコストは無料、あるいは低コストに抑えられるため、予算を気にすることなく試行錯誤を繰り返せるのが特徴です。
サンドボックス上での運用は、セキュリティ性に優れるため外部からの攻撃で流出するようなリスクも回避できます。複数のサーバーに対してリクエストを分散し、発生する負荷に対して柔軟にスケールする強みも備えている点はメリットです。
また、スタンダード環境では稼働時間に応じた課金が行われます。サーバーを使わなければ料金は発生しないので、、費用対効果が最も高い料金体系と言えるでしょう。
2. フレキシブル環境
フレキシブル環境においては、以下のような特徴を備えているのが特徴です。
Google Compute Engine上のDockerコンテナ内で実行される
スケーリング処理を細かく制御できるアプリケーション開発ができる
使用したvCPU、メモリー、ディスク量に応じて課金が発生
フレキシブル環境の場合、GAEは仮想マシンであるGoogle Compute Engine上のDockerコンテナ内で動作します。任意で用意しているDockerコンテナを使い、独自性の高いカスタムライブラリの運用が可能です。
自動化されたスケーリング機能を使用し、リソースの不足が見られた場合には、あらかじめ予約しておいたCompute Engine VMが優先されやすくなります。仮想マシンのインスタンスについては定期的にヘルスチェックが行われ、利用可能な更新がある場合には毎週自動的に再起動されるのが特徴です。
また、料金体系は従量課金性ではあるものの、vCPU、メモリー、ディスク量の使用量に応じているのが特徴です。スタンダード環境とは少し仕様が異なる点には気をつけておきましょう。
Google Cloud ダッシュボードで可視化する方法
続いて、Monitoringのダッシュボードで可視化する方法をお伝えします。
今回は実際に監視対象となる環境を用意するべく、公式で採用されている環境にてアプリケーションを構築しましょう。
環境
・GAEの環境の種類:フレキシブル
・Python:3
アプリケーションの用意が終わりましたらダッシュボードの作成に移ります。
Monitoring > ダッシュボード
ダッシュボードを作成します。
グラフを追加します。

今回は作成したアプリケーションへのアクセスの何割がクライアントエラーであったか表示するグラフを作成します。
まずはレスポンスコードが400系のエラー数を分単位で集計するよう次のように設定します。
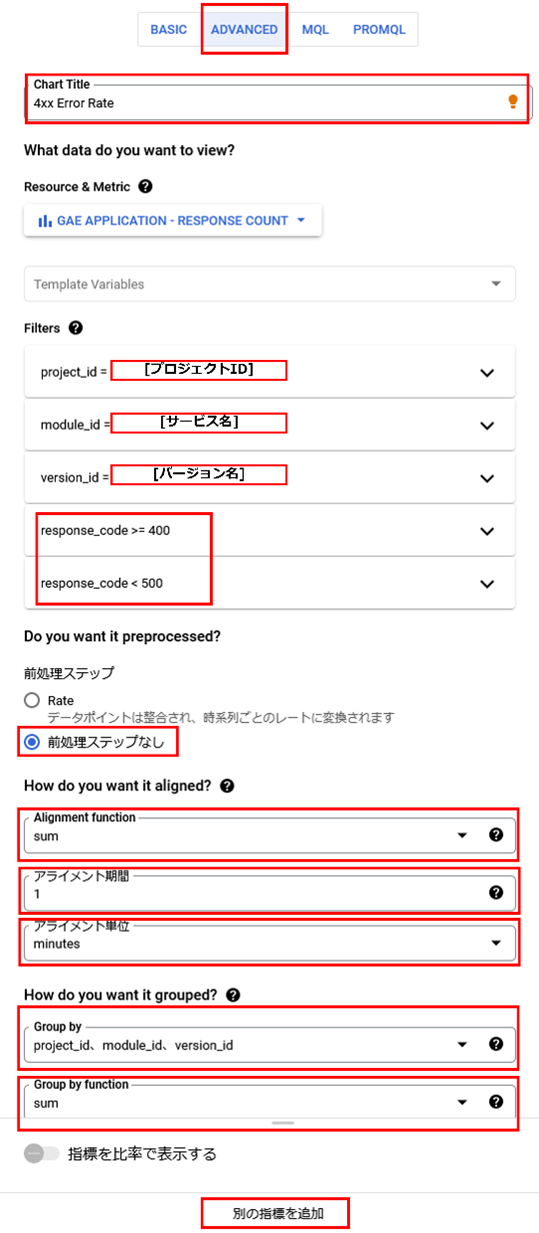
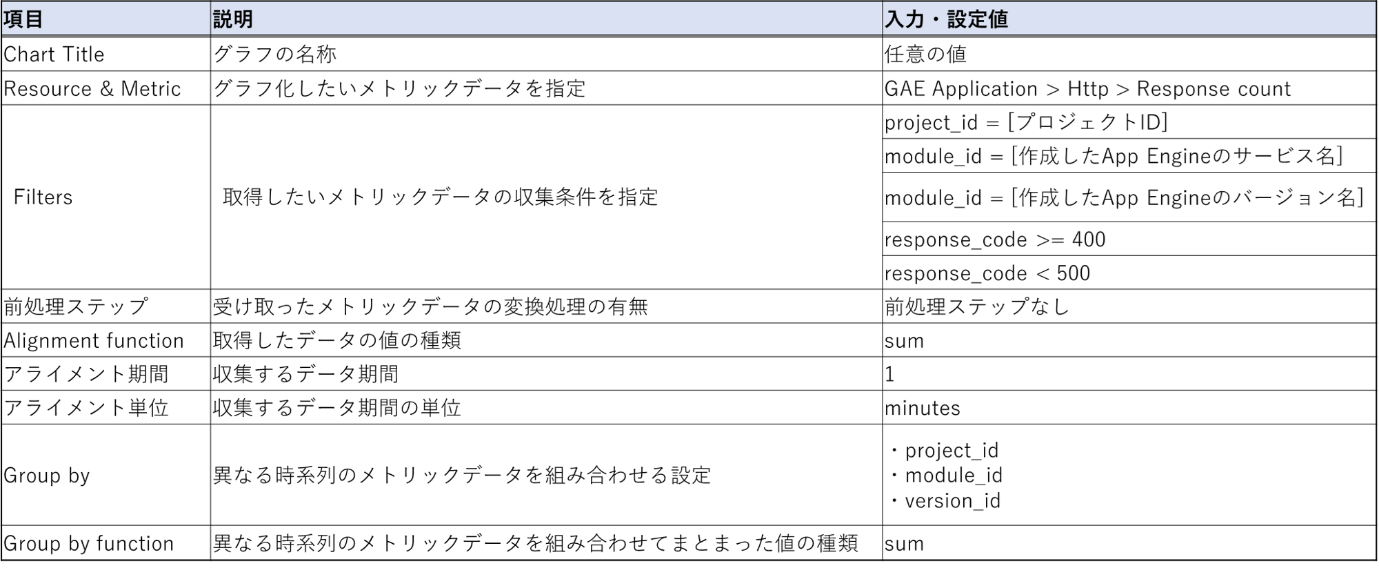
各入力値の設定内容については以下の通りです。
フィルター設定を行うことで特定のアプリケーションやレスポンスコードの折れ線グラフ化することができます。
さらにグルーピングを行うことで一つの線にまとめて表示することができます。
今回はクライアントエラーの比率を可視化したいので「別の指標を追加」をクリックし、分母となるメトリックデータの収集設定を行います。
先述の設定とは異なる点として、Filtersのresponse_codeの条件を指定しないことが挙げられます。。
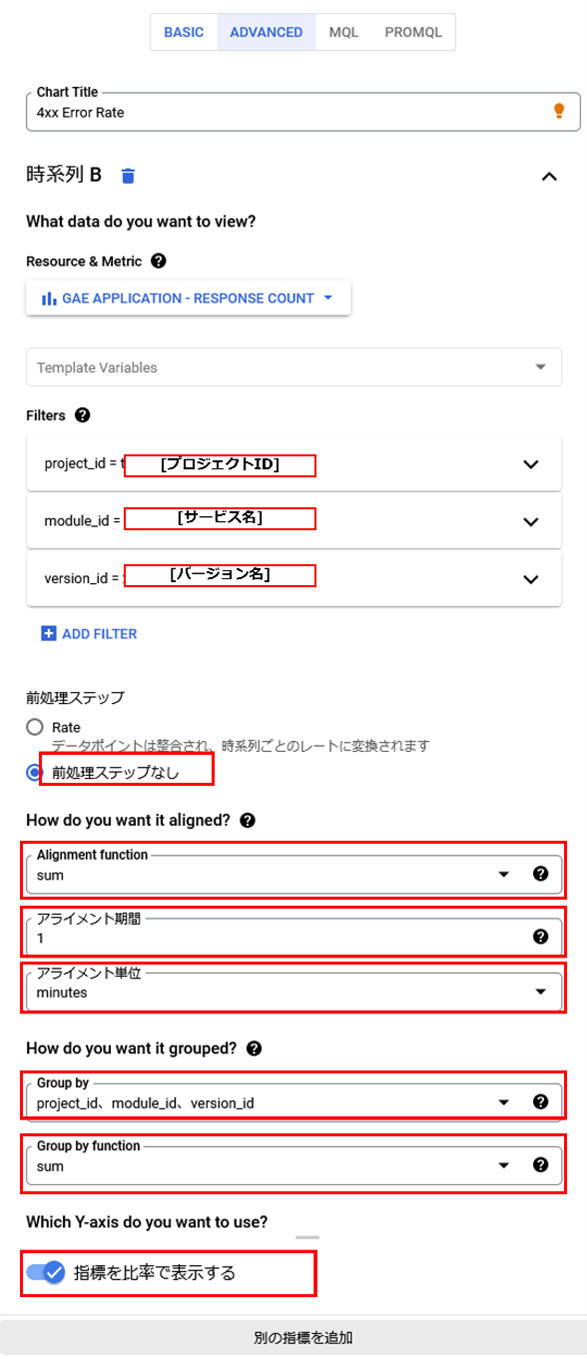
エディタを閉じると次のようなグラフが作成され、可視化することが出来ます。
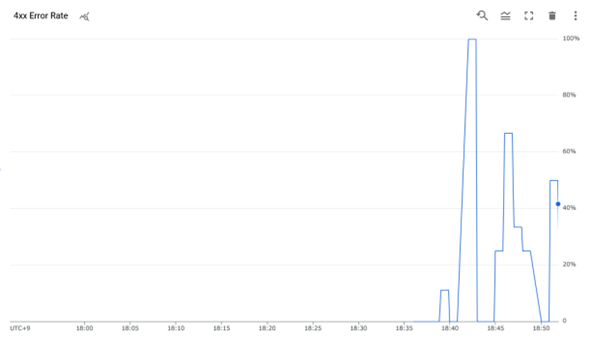
これで、アプリケーションへのアクセスの何割がクライアントエラーであったかを表示するグラフが作成できましたしました。以降ではアラート通知する方法を試していきます。
アラート通知する方法
Monitoringで通知チャンネルの設定とポリシーの作成を行い、アラート通知する方法をお伝えします。
まずは通知先となるチャンネル(Eメール) の作成を行います。
GCPコンソールにログインし、Cloud Shellを起動します。
通知先を設定するためのファイルを作成します。
$ vim email-channel.json{
"type": "email",
"displayName": "email alert notifications",
"description": "for app engine 400s error rate notification",
"labels": {
"email_address": "通知先のメールアドレス"
}
}作成したファイルを使ってEメールの通知チャンネルを追加します。
$ gcloud beta monitoring channels create --channel-content-from-file="email-channel.json"設定がうまく行われた場合、次のようなメッセージが表示されます。
Created notification channel [projects/<プロジェクトID>/notificationChannels/<識別子>] .
次にアラートポリシーを作成します。
今回はクライアントエラーが30%を超えた場合にアラートを通知するようにポリシーを設定します。
$ vim monitoring-policy_4xxErrorRate.json{
"displayName": "HTTP 400s error rate",
"combiner": "OR",
"conditions": [
{
"displayName": "App Engine HTTP 400s error rate exceeds 30 percent",
"conditionThreshold": {
"filter": "metric.label.response_code>=\"400\" AND
metric.label.response_code<\"500\" AND
metric.type=\"appengine.googleapis.com/http/server/response_count\" AND
project=\"[プロジェクト名]\" AND
resource.type=\"gae_app\"",
"aggregations": [
{
"alignmentPeriod": "300s",
"crossSeriesReducer": "REDUCE_SUM",
"groupByFields": [
"project",
"resource.label.module_id",
"resource.label.version_id"
],
"perSeriesAligner": "ALIGN_DELTA"
}
],
"denominatorFilter": "metric.type=\"appengine.googleapis.com/http/server/response_count\" AND
project=\"[プロジェクト名]\" AND
resource.labels.version_id = \"[バージョン名]\" AND
resource.labels.module_id = \"[サービス名]\" AND
resource.type=\"gae_app\"",
"denominatorAggregations": [
{
"alignmentPeriod": "300s",
"crossSeriesReducer": "REDUCE_SUM",
"groupByFields": [
"project",
"resource.label.module_id",
"resource.label.version_id"
],
"perSeriesAligner": "ALIGN_DELTA"
}
],
"comparison": "COMPARISON_GT",
"thresholdValue": 0.3,
"duration": "0s",
"trigger": {
"count": 1
}
}
}
],
"notificationChannels": "projects/[プロジェクトID]/notificationChannels/[作成した通知チャンネルID]"
}作成したファイルを使ってアラートポリシーを追加します。
$ gcloud alpha monitoring policies create --policy-from-file="monitoring-policy_4xxErrorRate.json"設定がうまく行われた場合次のようなメッセージが表示されます。
Created alert policy [projects/<プロジェクトID>/alertPolicies/<識別子>] .
また、Monitoringコンソールで確認するとポリシーが設定されていることが確認できます。

今度は作成したアプリケーションにアクセスし、通常のアクセスとクライアントエラーが発生するアクセスを行い、エラー比率に応じてアラート発生するか確認してみます。
通常のアクセス:https://[プロジェクトID] .an.r.appspot.com
クライアントエラーが発生するアクセス(404エラー):https://[プロジェクトID] .an.r.appspot.com/test
すると、ポリシーで表示されるグラフは次のように表示されます。(緑枠参照)
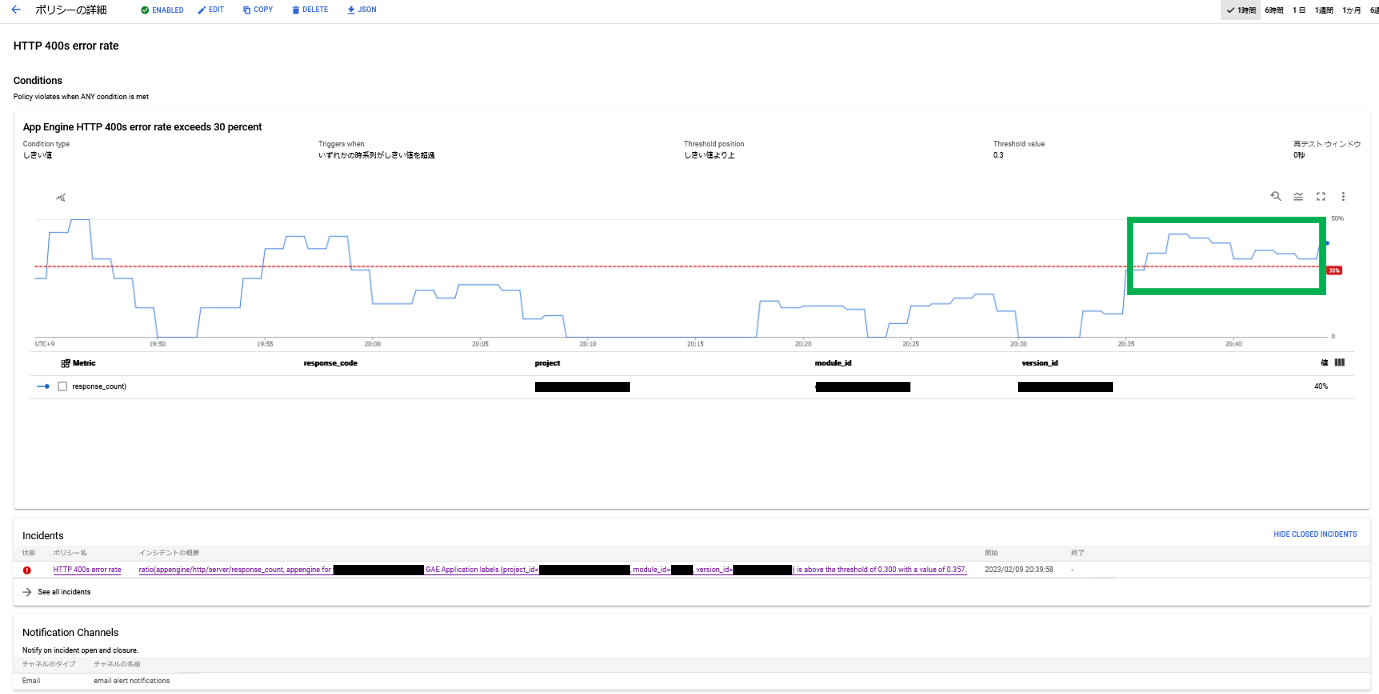
クライアントエラーの割合の閾値が30%で設定されていることが確認でき、実際に次のようなアラートメールを受け取ることができます。
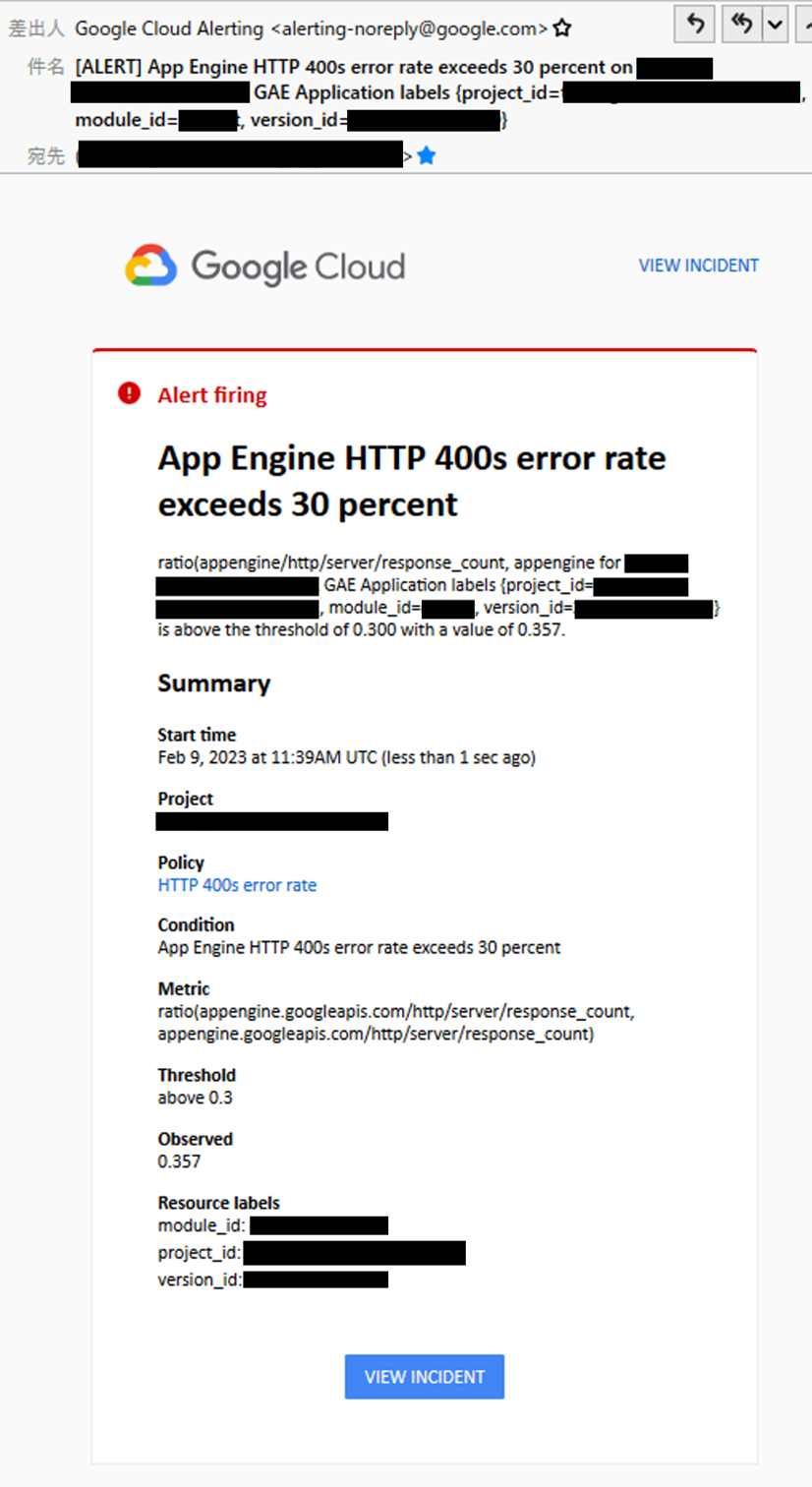
以上で、Monitoringで通知チャンネルの設定とポリシーの作成を行い、アラート通知する方法が完了しました。
終わりに

今回は、GAEを運用する上で知っておきたい基本的な概要、そして覚えておきたい運用方法の一例を解説しました。
GAEで作成したアプリケーションのクライアントエラーの比率を一例にMonitoringダッシュボードで可視化し、Monitoringポリシーでアラート通知する方法は、導入時に試しておきたいアプローチです。またこの機能を活用すれば、フィルター条件を変更することでサーバーエラー比率の可視化や監視が行うことができます。
加えて、通知チャンネルはEメールに限らずPub/SubやSMS、Slackなどへの通知も可能です。
実際に検証してみた結果、比率のグラフ化は行えてもアラート通知させるためには設定ファイルを用意しgcloudで設定しなければなりません。設定ファイルで定義した内容を理解し、Aggregationの概念的な理解が求められると、取り掛かりにくいと感じてしまいました。
以上のことから、公式ドキュメントや噛み砕いて表現してくれる情報をもとに理解を深めながら設定することが大切と言えるでしょう。
