

AWS障害情報を確認する方法とは?障害に備える4つの対策も解説!
AWSは現在、多くの企業が提供するサービスや金融・行政機関のシステムに広く導入されています。当然ながら障害が発生した場合の影響範囲は大きく、過去にもサービスやシステムの停止が発生してきました。AWSを利用する企業にとって、突然障害が発生した際にその情報を確認する手段の確保は必須です。
「リアルタイムな障害の情報はどこで確認したらいい?」
「障害に備えるにはどんな対策が必要?」
こういった疑問に答えるため、本記事ではAWS障害の概要、確認方法、障害の実例、障害が発生することによって想定されるリスク、障害の対策について解説していきます。
既にAWSを導入している企業の方も、これから導入を検討されている方も、これを読めばAWSの障害を確認する方法を網羅できます。実例や対策を踏まえて今後のAWS活用に役立てていきましょう。
AWSの「障害」とは

AWSの障害は、AWSが管理するネットワークやハードウェアが正常に動作しなくなった場合に発生します。AWSでは高い可用性を保証しており、想定されるあらゆる障害に対応できるよう対策が施されています。とはいえ、インターネット上のシステムにおいて人的・外的要因に関わらず障害は発生するのが前提です。AWSの障害管理に関するドキュメントでも、冒頭で以下のように記述されています。
障害は発生するものであり、最終的にはすべてが時間の経過とともにフェイルオーバーします。つまり、ルーターからハードディスクまで、TCP パケットを破壊するオペレーティングシステムからメモリユニットまで、そして一時的なエラーから永続的な障害まで、どれもが対象となるのです。これは、最高品質のハードウェアを使用しているか、最低料金のコンポーネントを使用しているかにかかわらず、当たり前のことです – Werner Vogels、CTO – Amazon.com
AWSで発生する障害の原因には主に「AWS側のマシントラブルやバグ」「人為的なミス」「トラフィックの過負荷」「天災」などがあります。これらが原因で発生する障害は、前述の通り発生するものと考えて設計を行わなくてはなりません。
AWSの障害を確認する方法
万が一サービスやシステムに異常があり障害が発生した場合、原因の切り分けが必要になります。それがAWS側の障害なのか、ユーザー側の局所的障害なのかによって、その後の対応が変わってくるためです。そこでここからは、AWSを利用している場合に障害情報を確認する方法を詳しく解説します。
AWS公式から発出されている情報に加えて、その他のサービスで障害を確認できるツールもご紹介していきます。
AWS Health Dashboard
AWS Health Dashboard はすべてのAWSサービスの状態を確認できます。ここでは発生した障害の情報を含めたAWS上のイベントが表示可能です。
「サーバーに接続できない」「サービスが利用できない」といった場合は、ここに表示される情報を確認してみましょう。大規模な障害などが発生している場合、未解決の問題として表示されます。情報を更新することができるため、AWSのコンソールにアクセスできる状態でリアルタイムの障害を確認したい場合に最適です。
【実際の確認方法】
①AWS Health Dashboard にアクセスします。
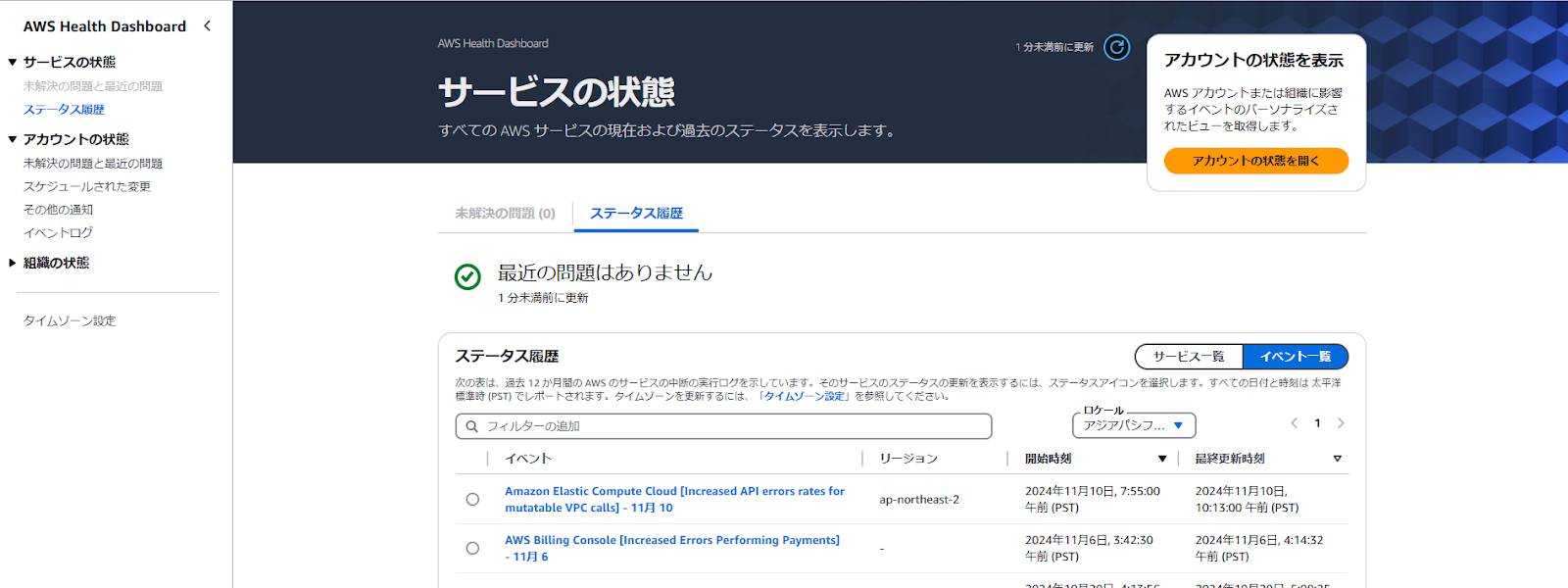
※既にAWSコンソールにアクセスしている場合は、[AWS Health Dashboards – アカウントの状態] ページにリダイレクトされます。
![[AWS Health Dashboards - アカウントの状態] ページ](https://ops-today.com/wp-content/uploads/2025/01/AD_4nXeBgsopCO25A9qVXlDS13vASGmcSOJywTTd7K3vV_CDSjjcP7dLTCe72vYm-Oy4dTOIaRBXEcV3Hf3oPA_VOsRwooU0otIzXYMJjiRBmTUwt2s5WT3HZHXYF8blJT4EN6JJ26Kn.png)
②左側の[サービスの状態]から[未解決の問題と最近の問題]を選択すると、AWSのサービスで直近に発生しているイベントが表示されます。影響を受ける地域やサービスの一覧を確認し、自社のサービスやシステムが影響範囲に含まれているか確認しましょう。
※特に問題となるイベントが発生していない場合、[未解決の問題と最近の問題]はグレーアウトして選択できない状態になります。
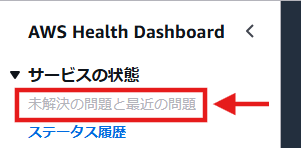
③左側の[アカウントの状態]から[未解決の問題と最近の問題]を選択すると、アカウントに固有のAWSリソースで直近に発生しているイベントが表示されます。ここに表示される問題は、いずれも直接自社のリソースに発生している問題です。脅威度や障害の内容を十分に確認して、適切に対応しましょう。
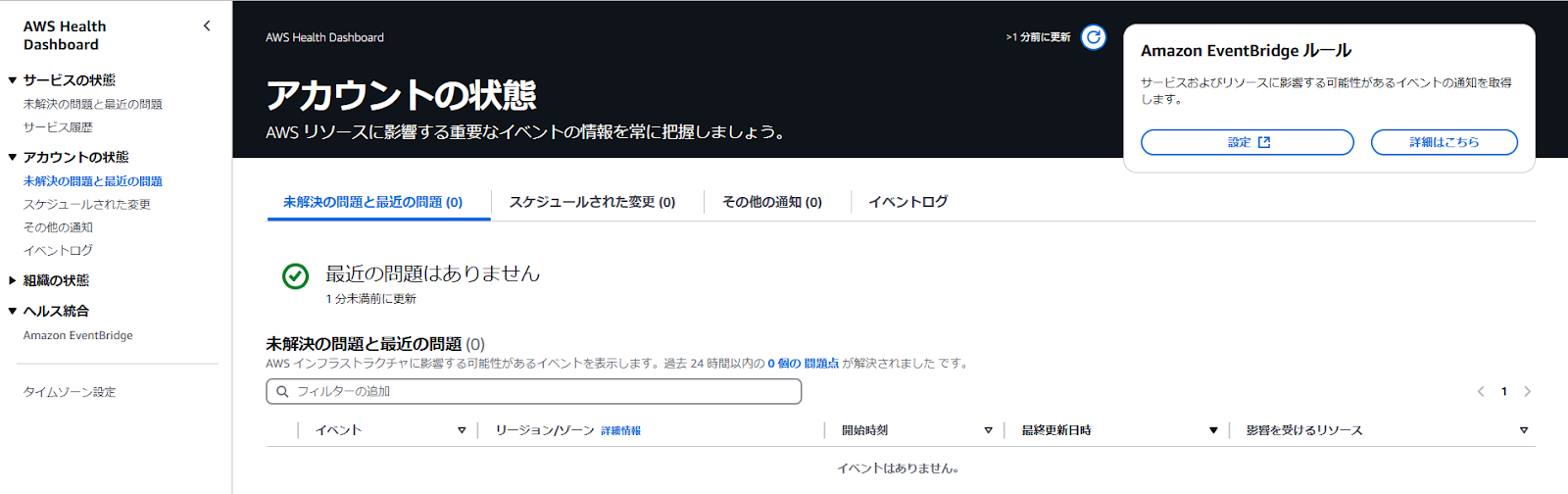
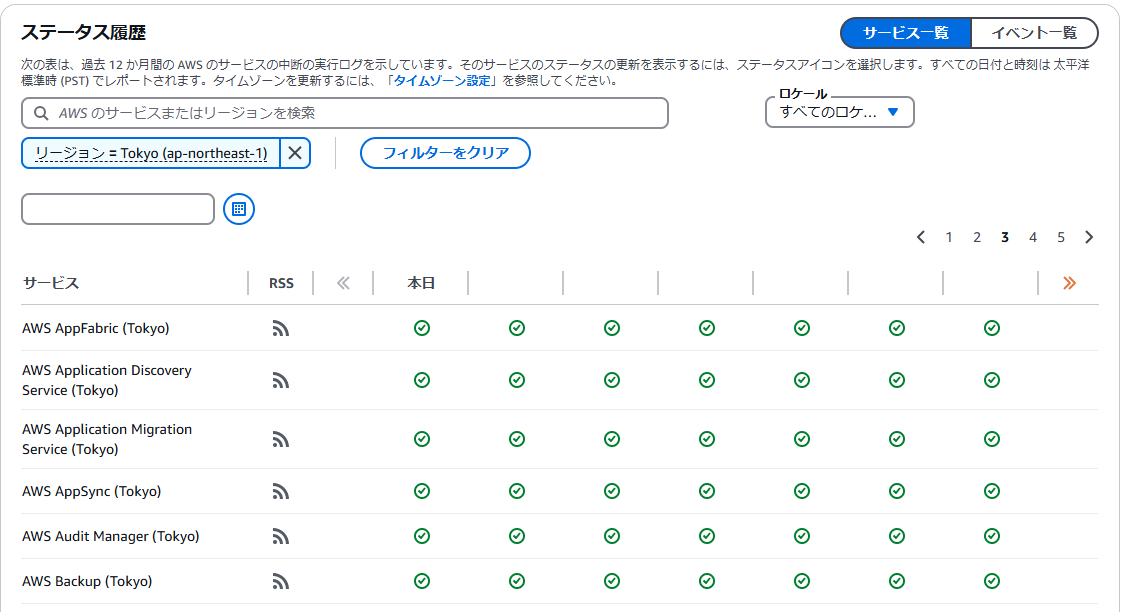
④サービスごとの状態を確認したい場合は、左側の[サービスの状態]から[ステータス履歴]の[サービス一覧]を確認します。ここには過去12か月間のAWSサービスの状態が表示されます。
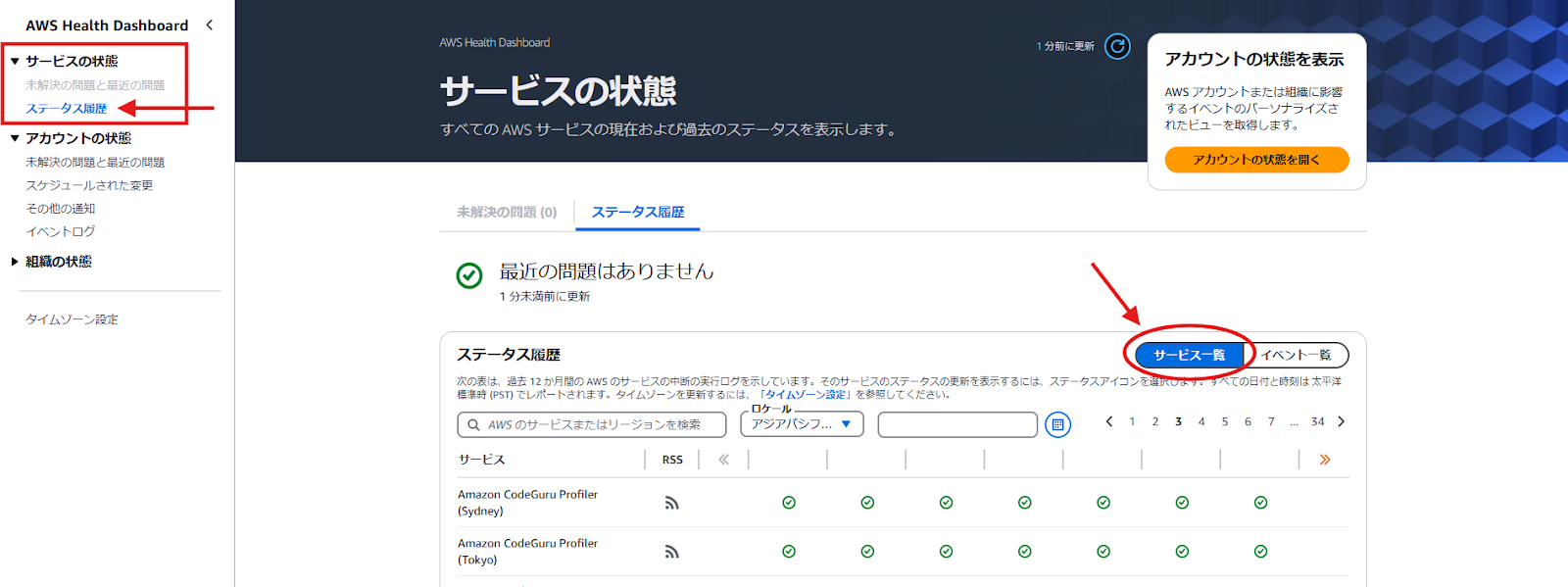
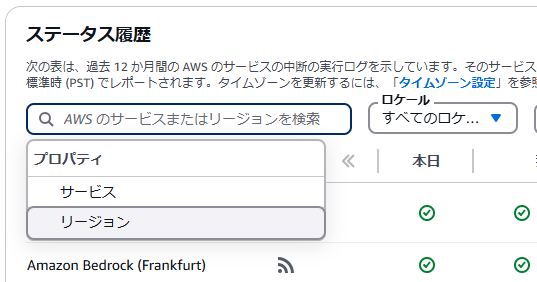
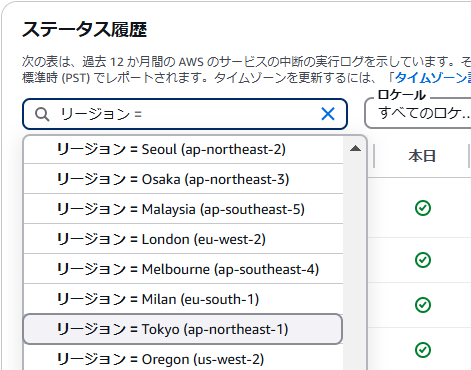
ステータス履歴内で東京リージョンの情報を確認する場合は、「AWSのサービスまたはリージョンを検索」から[リージョン]を選択します。選択肢の中から[Tokyo(northeast-1)]を選択すればフィルターがかかり、東京リージョンの履歴だけを確認可能です。
Post-Event Summary
AWS公式が提供している障害に関する情報として、他にPost-Event Summaryがあります。障害が発生した場合に、その規模や影響範囲が大きくユーザー側に重大な影響があった場合に公開される情報です。詳しい原因や事象の解決までの流れが解説されています。
欠点として、問題の解決後に公開される情報であるため、リアルタイムに発生している障害を確認する方法にはならない点があります。過去にあった障害の事例を参考にしたい場合や、障害が解消されたことの再確認に利用しましょう。
【実際の確認方法】
①AWS Post-Event Summary にアクセスします。

②自身が確認したい障害について記載されたリンクをクリックして、内容を確認します。
Downdetector
Speedtest.netを運営するOokla社が手掛ける障害確認用ツールです。AWSに限らず世界中の数千に及ぶサービスの障害情報を収集・提供しており、リアルタイムに情報を取得することができます。一方で、SNSや個人からの報告で障害を判断する仕組みであるため、誤検知が含まれる場合がある点に注意が必要です。
【実際の確認方法】
①Downdetector にアクセスします。
②ページ内に表示されているサービスの中から、AWSを選択します。
③AWSに障害に関するユーザーレポートが寄せられているか確認します。
何か問題が報告されていれば、画面上にその内容が表示されます。
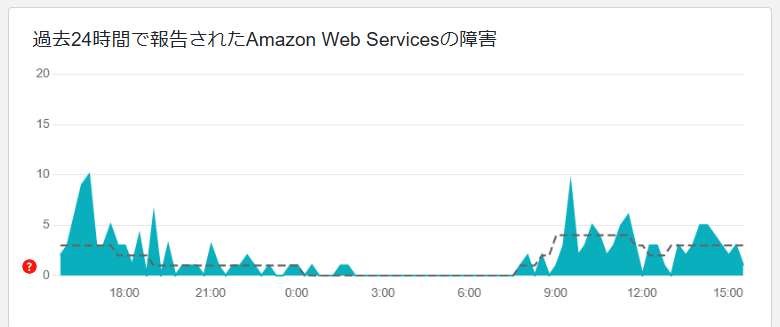
過去に発生したAWS障害
ここでは過去に実際に発生したAWSの障害について、原因や経過を解説します。
以下に示す2つの事例は、いずれも日本の東京リージョンで発生した障害です。
2021年9月:ネットワークデバイスの異常
2021年9月2日に東京リージョンで、AWS Direct Connect上の接続トラブルとパケットロスが発生しました。顧客のVirtual Private Cloud(VPC)が存在する東京リージョンのデータセンターネットワークへのパス上で、ネットワークデバイスの一部に障害が発生したことが原因と発表されています。
この障害で銀行系スマホアプリや電子決済サービスの他、航空会社のチェックインシステムに障害が発生しました。
約6時間後にAWS Direct Connectの動作が復旧し、通常の動作に戻りました。
参考:東京リージョン(AP-NORTHEAST-1)で発生したAWS Direct Connectの事象についてのサマリー
2019年8月:空調設備システムの異常
2019年8月23日に東京リージョンの単一のアベイラビリティゾーンで、オーバーヒートにより一部のEC2サーバーが停止しました。原因は該当のアベイラビリティゾーンの空調設備管理システムの障害でした。冷却に使用する空調設備が機能せず、オーバーヒートに繋がった事例です。
この障害では郵便局や一部のショッピングサイトの他、電子決済サービスなども利用システムが停止する事態となりました。
約3時間後に冷却装置が復旧し、障害発生から約6時間後に大部分のEC2インスタンスとEBSボリュームが復旧しました。
参考:東京リージョン (AP-NORTHEAST-1) で発生した Amazon EC2 と Amazon EBS の事象概要
AWSの障害で生じるリスク

AWSで障害が発生した場合、障害の影響範囲や原因によって様々な影響があります。それらの影響はいずれも、AWSを利用する企業にとってビジネス上のリスクです。どのようなリスクが想定されるのかを正しく認識し、対策を検討することで被害を最小限に抑えましょう。
システムにアクセスできなくなる
AWSで障害が発生しサーバーがダウンするかトラフィックが不通になった場合、システムへアクセスできなくなります。システムを利用していたアプリケーションなどがあれば、それらも稼働停止となります。
システムにアクセスできないのは、管理者だけでなくユーザーも同様です。AWSを利用したオンラインショップや予約サービスなどがアクセス不可となれば、そのダウンタイム分の損失が発生します。WEBサイトが表示されない、決済が利用できないといった状態が長引かないように対策が必要です。
データが破損・消失する
AWSの障害が発生した際にデータの送受信や保存が行われていた場合、完了前のデータが破損する恐れがあります。障害から復旧しても発生前の状態に戻せず、大規模なロールバック(データの巻き戻し)が発生すると、膨大な対応工数が発生します。運が悪ければデータ自体が消失して、復元できない状態となる可能性もあるため対策が必須です。定期的なバックアップを外部に保管して、復元が可能な状態を保ちましょう。
データを保存するデータベースに障害があり、一時的にデータが参照できなくなっているパターンもあります。この場合、表示できないだけでデータ自体は消失していないため、焦ってロールバックや復元を進めないように注意が必要です。原因の切り分けと確認を行ってから、対応を進めましょう。
顧客からの評価が下がる
顧客が利用するシステムやアプリケーションが停止すれば、顧客からの評価が下がる可能性があります。特に対象となる顧客が企業で、業務に利用するシステムを提供している場合に注意が必要です。設計や要件定義の段階で、顧客とダウンタイムの取り決めをしていても、実際に発生すれば早急な回復が求められます。ダウンタイムが長引けば、顧客の業務やビジネスそのものに影響が出てしまい、悪い評価へと繋がります。長期的に築いてきた評価やイメージが悪くなれば、その後の自社の信頼性にも悪影響です。
顧客の離脱や企業価値低下を防ぐために、事前の対策と発生時の迅速な対応が求められます。
復旧や経過観察にコストが生じる
実際に障害が発生した際、復旧対応は急務です。担当者がシステムの状態を確認し、原因の切り分けと対策を講じるのには、当然人件費が発生します。また、障害の発生が営業時間内とは限りません。営業時間外に長時間の対応を必要とする場合もあります。
また、本格的な復旧に専門家の協力や外部の診断を経る必要があるケースもあり、それらのコストも考慮しなくてはなりません。
復旧後もデータの修復や設計の見直しにコストが発生し、継続してシステム監視も必要です。システムが完全に復旧したといえる段階まで、大きなコストが発生すると考えた方が良いでしょう。
4つのAWS障害対策

AWSの障害に備えるためには、事前の対策が必要です。そこで広くAWSのサービスで利用できる障害対策を以下の4つにまとめました。これらの対策で障害発生時のダウンタイムを最小限にし、リスクを抑えたシステム設計を行いましょう。
障害を前提に設計する
前述の通りAWSの障害は、「発生するもの」として考えるべき課題です。そこで、障害を前提に設計をすることで被害を最小限に抑える方法が対策として有効です。AWSのベストプラクティスにおいても、システムの稼働が常に継続できる高い可用性を備えた構成が推奨されています。ここでいう「高い可用性」は、システムに障害が生じにくく、発生してもダウンタイムの短い状態を意味する表現です。
具体的にはインスタンスの冗長化や、複数のアベイラビリティゾーンにまたがった構成によって高可用性を実現します。AWSの一部がダウンしても、稼働し続けられるシステムを設計しましょう。
リスク分散を考慮して運用する
構築するシステムを1つのアベイラビリティゾーンやVPCにまとめると、そのゾーンがダウンした時点でシステムが停止してしまいます。そこでシステム内のリソースを複数のアベイラビリティゾーンに分散配置するなど、リスク分散を考慮して設計・運用する対策が重要です。
ただし、一部のリージョンに障害が発生した場合、アベイラビリティゾーンを分けていてもバックアップごと利用できなくなる可能性があります。そこで、S3やEBSなどに保存されたデータのバックアップ先に別のリージョンを選ぶ方法も有効です。この方法であればリージョン単位の障害にあっても、バックアップしたデータからすぐに復旧が可能になります。
障害発生に対応するための設定を行う
AWS上の障害発生を常に監視するために人的リソースを割くのは現実的ではありません。そこで、AWSのリソースを監視できるサービスを利用して、監視および異常発生時の通知を行えるよう設定をしておきましょう。
具体的に利用できるサービスとして「Amazon CloudWatch」「Amazon Simple Notification Service(Amazon SNS)」があります。
Amazon CloudWatch は、AWS上のリソースをリアルタイムで監視してメトリクスを収集できるサービスです。特定のサービスやメトリクスの動きに対して基準となるしきい値を設定すれば、そこを超過した時に通知を送信できます。例えば、システムに利用しているEC2インスタンスのCPU使用率が80%を超えたときに通知を出せば、過負荷を確認して追加のインスタンスを起動するか検討することができます。この通知に使うサービスが、Amazon SNSです。
詳細設計の段階で異常検知用にこれらを導入して、障害に迅速に対応できるようにしておきましょう。また、これらの設定は必ず設計書や仕様書に記載を残すことをおすすめします。後からCloudWatch上の設定だけ見た場合に「何を通知しているのか」がわかりづらいケースがあり、担当者が変わると混乱を招くケースがあるためです。
障害発生試験を行う
障害が発生した際に迅速な対応ができるように、定期的に障害発生試験を行うのが対策として有効です。システムの構造に合わせた障害のシナリオを用意して、実際に対応を確認したり、復旧手順のテストを行います。
AWSでは障害発生試験に利用できるサービスとしてAWS Fault Injection Service (AWS FIS) があります。このサービスでは、EC2インスタンスの停止やRDS(データベース)の再起動など、いくつかの障害を疑似的に起こすことができます。障害発生に対するシステムの動きや応答を確認しつつ、担当者の訓練も実施することが可能です。
火災に備えた避難訓練のイメージで、定期的に担当する部署やチームで実施しましょう。
まとめ
AWSは高い可用性が保証された優秀なクラウドサービスです。しかし、ネットワーク上で機能するシステムである以上は必然的に障害が発生します。実際に日本の企業が多く利用する東京リージョンでも、障害は発生しています。サービスを利用する側である我々はそれを念頭に置いて、「いかに素早く障害を把握して適切に対応するか」を考えなくてはなりません。
本記事では、AWSの障害についての概要、障害の確認方法、過去の実例、障害によるリスク、障害への対策について解説してきました。
この記事が今後AWSの障害に備える上で、読者の方が関わるシステムの参考になれば幸いです。
